안녕하세요, 귀한 시간 내주셔서 정말 감사드립니다. 이번 프로젝트에서는 MSA(Micro Service Architecture) 기반 클라우드 네이티브 애플리케이션을 소개해 드리려 합니다. 이 프로젝트에서 중점적으로 강조하고 싶은 것은 기술적인 역량이며, 아래와 같은 순서로 설명하겠습니다.:
1.Project Overview: 프로젝트에 대한 전반적인 소개2.Technical Details: 프로젝트에서 기여한 부분에 대한 기술적인 내용3.Project Retrospective: 프로젝트에 대한 회고4.Reference: 참고 도서 및 코드 저장소 링크
이 프로젝트는 제가 가진 기술적인 역량을 가장 잘 보여줄 수 있는 프로젝트로, 2.Technical Details 부분을 위주로 봐주시면 감사하겠습니다.
📌 1. Project Overview
ZipBob은 MSA(Micro Service Architecture) 기반 클라우드 네이티브 백엔드 시스템으로 구현된 프로젝트입니다. 초기에는 프론트엔드와 백엔드를 모두 포함하는 풀스택 프로젝트로 기획되었으나, 프로젝트 진행 중 프론트엔드 개발자의 이탈로 인해 불가피하게 백엔드 시스템 구현에만 집중하게 되었습니다. 한정된 프로젝트 기간 내에서 최선의 결과물을 만들기 위해, 팀원들과 협의하여 프론트엔드를 새로 개발하기보다는 백엔드 시스템의 완성도에 중점을 두기로 결정하였습니다. 이 점 유의하여서 봐주시면 정말 감사하겠습니다.
1.1 프로젝트 주제
레시피 추천 및 냉장고 재료 관리 서비스의 백엔드 시스템
1.2 프로젝트 목표
- 비용 효율성, 빠르고 정확한 배포, 수평적 확장성, 고가용성, 안정성 그리고 관측 가능성을 갖춘 분산 시스템을 구축
- 레시피 추천 서비스를 위한 MSA 기반 Cloud Native Application 구현
- 쿠버네티스 기반 애플리케이션 구축
- CI/CD, 모니터링, 로깅 시스템 구축
- RAG 기반 레시피 추천
1.3 주요 기능
사용자 인증/인가- 회원 정보 생성/수정/삭제/조회
- 소셜 로그인
냉장고 재료 관리- 냉장고 재료 생성/수정/삭제/조회
- 냉장고 재료 소비기한 관리
- 보유 식재료 기반 레시피 추천을 위한 재료 정보 제공
레시피 추천- RAG 기반 레시피 생성
- 보유 식재료 기반 레시피 추천
레시피 리뷰 관리- 레시피 리뷰 생성/수정/삭제/조회
1.4 개발 환경
- 기간: 2024.10~2024.12
- 인원: 3명 (
백엔드1명,클라우드 인프라1명,AI1명) - 나의 역할 :
클라우드 인프라 - 기술 스택
- Backend
- Language :
Java 17 - Framework:
Spring Boot,Spring Security,Spring Cloud
- Language :
- Database
- RDBMS:
MariaDB - NoSQL:
MongoDB - Cache, Refresh Token Store:
Redis - Message Queue:
RabbitMQ
- RDBMS:
- Infra
- Public Cloud:
AWS - Container Orchestration:
Kubernetes - Container Runtime Interface:
containerd - Cluster Management:
kOps
- Public Cloud:
- DevOps
- CI/CD:
GitHub Actions,ArgoCD - Metrics Monitoring:
Prometheus,Grafana - Logging System:
EFK Stack(Elasticsearch,Fluentd,Kibana)
- CI/CD:
- AI
- Language:
Python - Framework:
FastAPI,LangChain
- Language:
- Backend
1.5 System Architecture
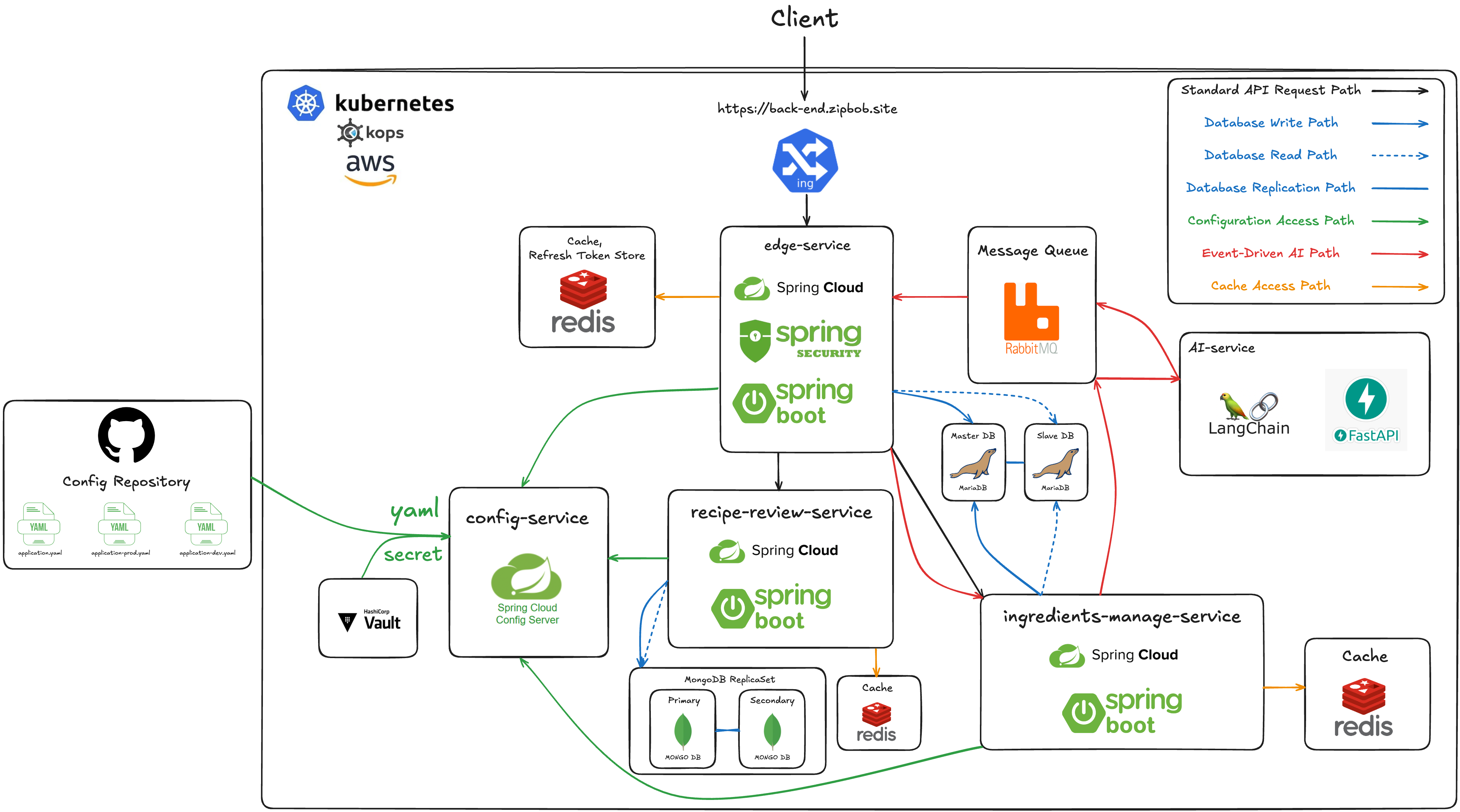
1.6 서비스 구성
Edge Service- Spring Cloud Gateway를 통한 라우팅
- JWT 기반 인증/인가 처리
- Spring Security와 OAuth 2.0을 활용한 소셜 로그인
- MariaDB를 활용한 회원 정보 관리
Ingredients Manage Service- MariaDB를 통한 냉장고 재료 관리
- 냉장고 재료 소비기한 관리
- AI 레시피 추천을 위한 보유 식재료 정보 제공
Recipe Review Service- MongoDB를 통한 레시피 리뷰 관리
AI Recipe Service- RAG 기반 레시피 추천
- RabbitMQ를 활용한 레시피 추천 비동기 처리
Config Service- Spring Cloud Config Server로 중앙식 설정 관리 구현
- Github Repository에 저장된 설정 데이터를 모든 애플리케이션에 전달
- HashiCorp Vault 연동을 통한 민감 정보 보안
- Spring Cloud Bus와 RabbitMQ를 통한 설정 변경 사항을 Application Runtime시에 적용
1.7 DevOps Architecture
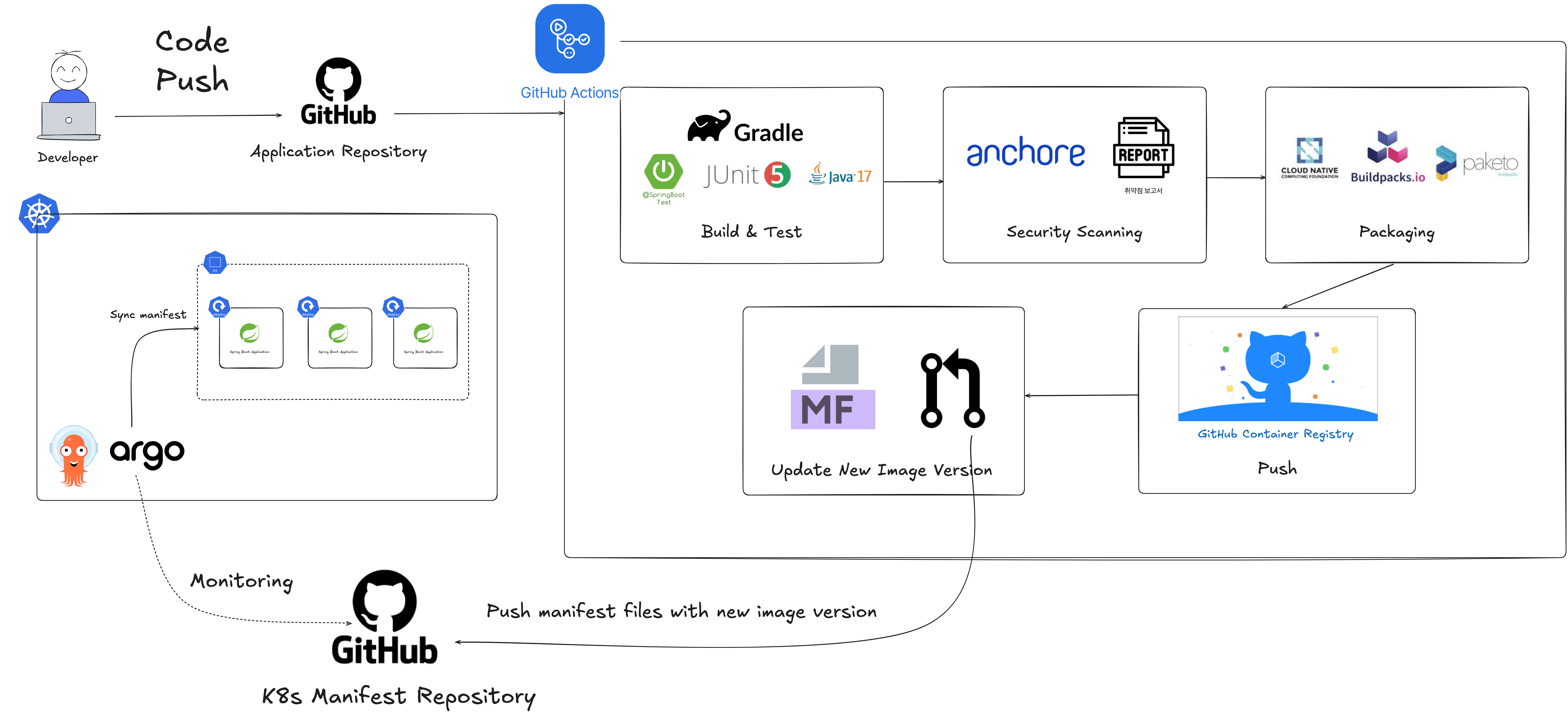
1.7.1 CI/CD Pipeline (GitHub Actions, ArgoCD)
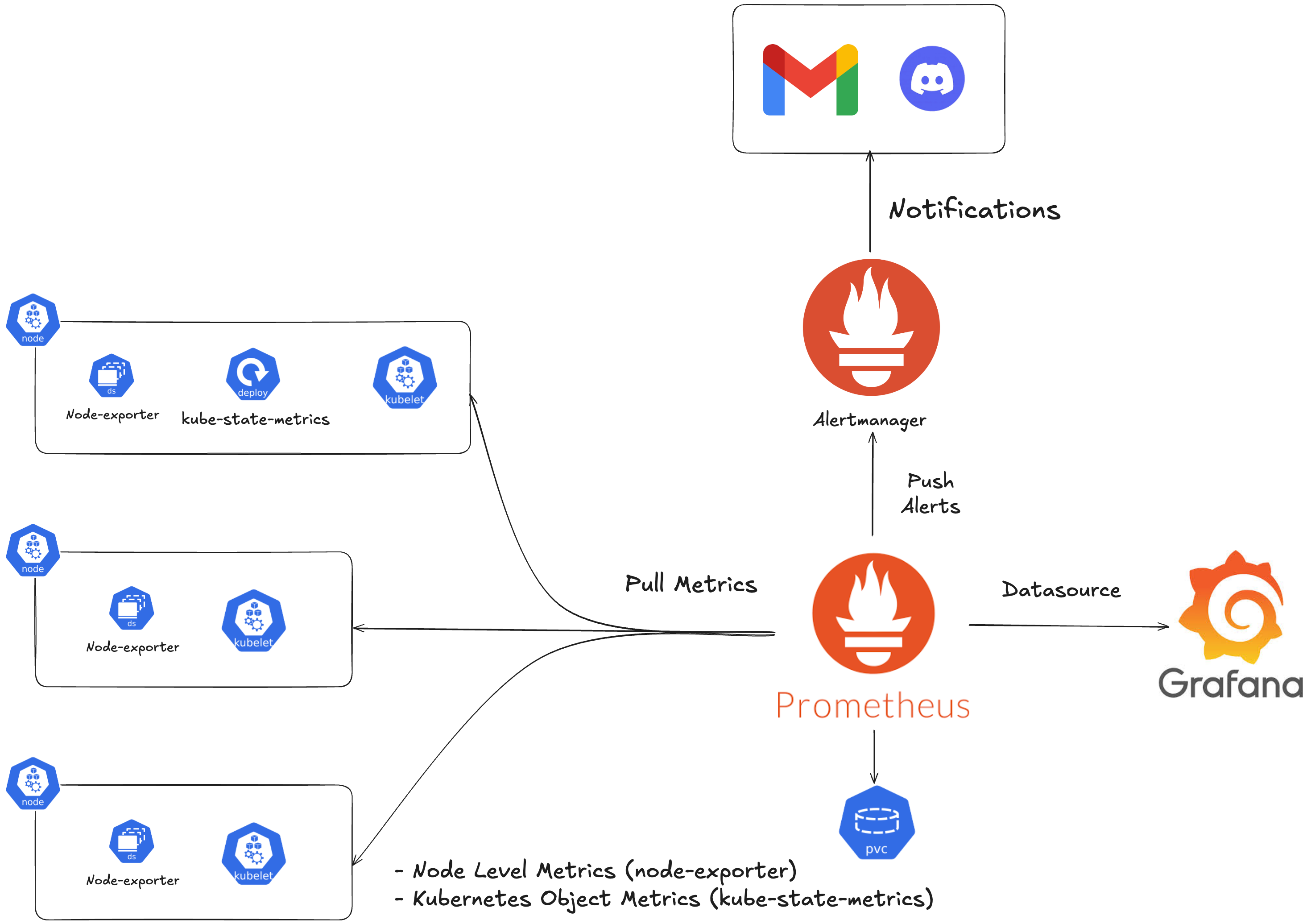
1.7.2 Metrics Monitoring (Prometheus, Grafana)
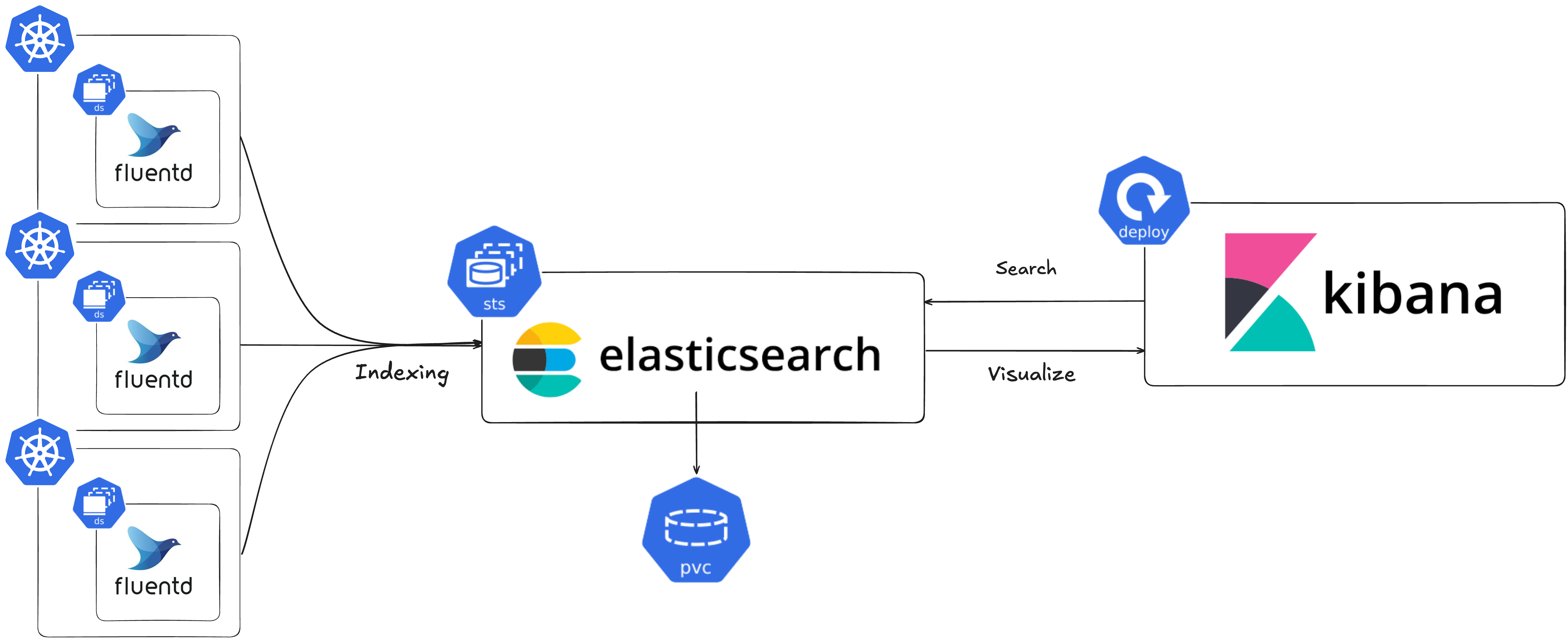
1.7.3 Logging System (EFK Stack)
1.8 API Documentation
1.9 ERD(Entity-Relationship Diagram)

🛠 2. Technical Details
이번 프로젝트에서 저는 클라우드 인프라 파트를 담당하여 쿠버네티스 기반 클라우드 네이티브 애플리케이션의 아키텍처를 설계하고, 해당 아키텍처를 기반으로 개발 및 서비스 운영에 필요한 모든 인프라를 구축하여 모든 애플리케이션을 해당 환경에 배포하였습니다. 또한 백엔드 서비스 중에서는 Recipe Review Service를 개발하였습니다.
구체적으로 제가 한 역할은 크게 다음과 같습니다:
프로젝트 진행 방식은 다음과 같습니다:
- MSA 기반 클라우드 네이티브 아키텍처를 주도적으로 설계하여, 백엔드 개발자의 피드백을 반영하여 실현할 수 있는 아키텍처를 설계
- 개발 및 서비스 운영에 필요한 모든 인프라를 구축하고 해당 환경에 전체 애플리케이션의 배포
- 백엔드 개발에서는 Ingredients Manage Service를 참고하여 Recipe Review Service를 개발
2.1 System Architecture
이번 프로젝트에서는 MSA(Micro Service Architecture)를 채택했습니다. 이는 Cloud Native Application의 주요 특성인 확장성(Scalability), 느슨한 결합(Loose Coupling), 관리 용이성(Maintainability), 복원력(Resilience)을 고려하여 결정했습니다.
이를 바탕으로 ZipBob의 백엔드 시스템을 여러 개의 독립적인 서비스로 나누고, 각 서비스의 구조와 서비스 간 상호작용을 설계했습니다. 이어지는 2.2 Deployment Architecture 섹션에서는 클라우드 내의 쿠버네티스 클러스터 환경에서 실제로 이 시스템 아키텍처를 어떻게 구축했는지 설명하겠습니다.
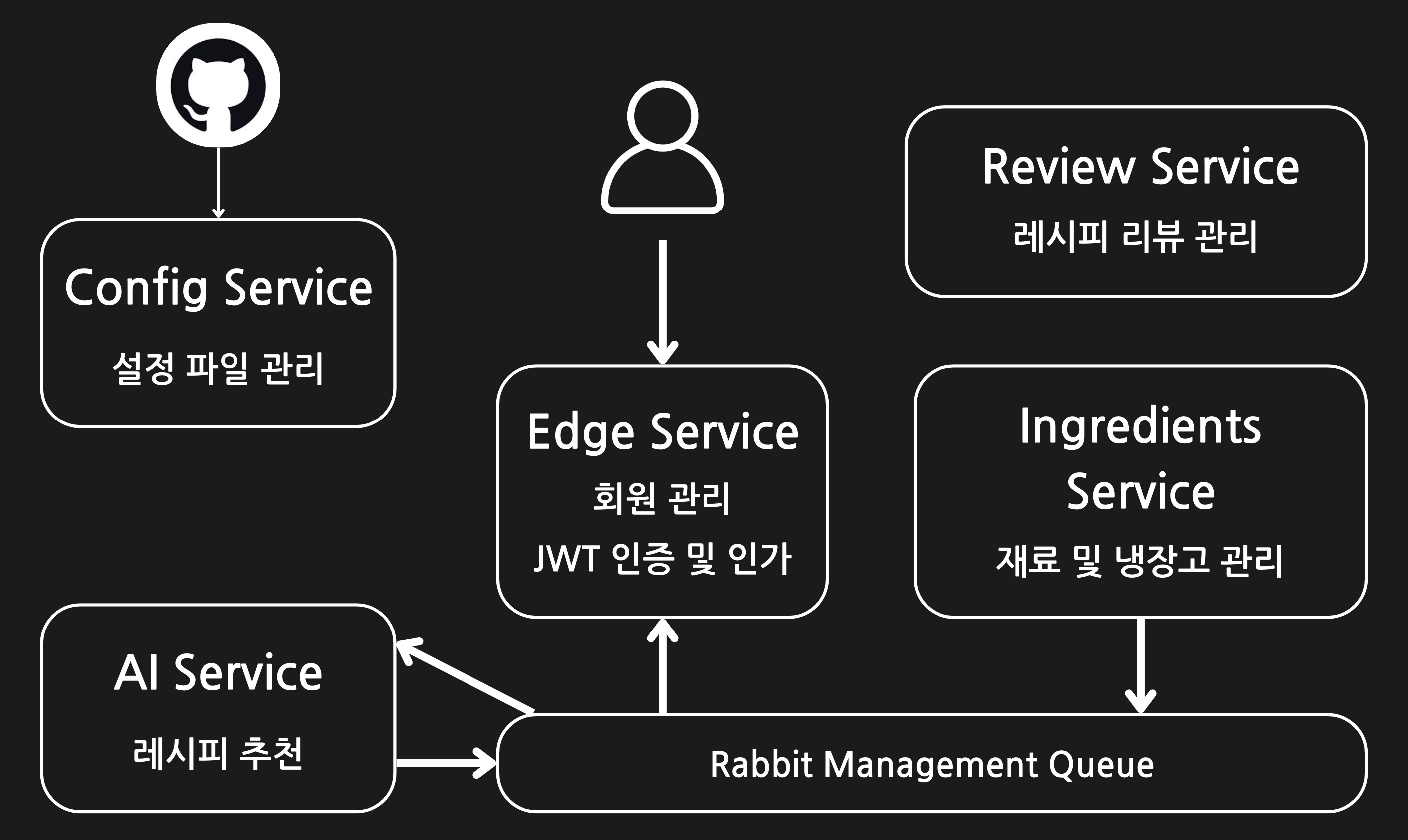
2.1.1 서비스 간 분리 및 상호작용
ZipBob 백엔드 시스템은 총 5개의 서비스로 구성되어 있으며, 각 서비스는 1.3 주요 기능에 따라 분리하였으며 중앙 집중식 설정 관리를 위해 config service를 추가하였습니다. 이 시스템에서 각 서비스는 독립적으로 동작하며, 기본적으로 REST API를 통해 동기적(Synchronous)으로 통신하며, 필요한 부분만 비동기적(Asynchronous)으로 통신하도록 설계하였습니다.
서비스 간 통신 방식에서 비동기적(Asynchronous) 통신은 데이터 처리 속도가 빠르고 서비스 간 느슨한 결합도(Loose Coupling)를 제공하는 장점이 있으나, 기본적인 상호작용 방식으로 동기적(Synchronous) 통신으로 선택한 이유는 다음과 같습니다.:
- 비동기적 통신은 분산 트랜잭션(Distributed transaction) 관리가 복잡함
- 비동기적 통신은 디버깅(Debugging)이 어려움
- 팀원들이 Spring MVC에 익숙하며, Spring WebFlux를 활용한 비동기 통신을 프로젝트 기간 내에 학습하고 적용하기 어려움
클라우드 네이티브 환경에서 서비스 간 동기적(Synchronous)인 통신 방식으로는 gRPC, REST API라는 옵션이 있으며, REST API 통신 방법을 선택한 이유는 다음과 같습니다.:
- 팀원들의 REST API에 대한 높은 이해도와 개발 경험
- 제한된 프로젝트 기간 내 새로운 통신 방식 (gPRC) 학습 및 적용의 어려움
5개의 서비스는 각각 다음과 같은 핵심 역할을 수행하며, 각 서비스의 상호작용은 다음과 같습니다:
2.1.2 Relation Database vs NoSQL Database
이번 프로젝트에서 Recipe Review Service를 개발하였고, 레시피 리뷰 데이터는 MongoDB를 사용하여 저장했습니다. 이번 파트에서는 레시피 리뷰 데이터의 저장소로 왜 RDB가 아닌 NoSQL을 선택했는지 그 이유를 설명하겠습니다.
먼저 레시피 리뷰 데이터가 생성되는 과정은 다음과 같습니다.:
- 외부 사이트의 레시피 데이터를 주기적으로 크롤링하여 Vector DB에 저장
- AI Service가 Vector DB의 레시피 데이터를 기반으로 사용자에게 레시피 추천
- 사용자가 추천받은 레시피에 대한 리뷰 작성
NoSQL을 사용한 첫 번째 이유는 레시피 리뷰 데이터의 확장성 때문입니다. 현재는 작성자 닉네임, 리뷰 내용, 별점과 같은 기본적인 데이터만 저장하고 있지만, 향후 크롤링을 통해 얻은 레시피 사진이나 조리 과정 영상, 재료 정보와 같은 다양한 형태의 데이터를 추가로 저장할 수도 있기 때문에 스키마 제약이 없는 NoSQL이 적합하다고 생각했습니다.
두 번째 이유는 레시피 리뷰 데이터가 가진 특징을 고려했습니다. 레시피 리뷰 몇 개가 일시적으로 누락되거나 불일치가 발생하더라도 서비스 운영에는 크게 문제 되지 않습니다. 또한 레시피 리뷰 데이터는 주로 작성하고, 조회하는 단순한 작업이 대부분이기 때문에 복잡한 트랜잭션 처리가 필요하지 않았습니다. 이러한 특징을 고려해 봤을 때 NoSQL 데이터베이스를 사용하는 것이 더 적합하다고 생각했습니다.
2.1.3 Database Master-Slave Replication
프로젝트에서 사용한 데이터베이스는 MariaDB와 MongoDB이며, 두 DB 모두 Master-Slave 구조로 구성하였습니다. Master 노드는 쓰기 작업을, Slave 노드는 읽기 작업을 담당하도록 설계했으며, Replication은 각 DB에서 제공하는 자체적인 기능을 활용하였습니다.
현재 서비스 규모에 비해 다소 과도한 설계일 수 있으나, 다음과 같은 이유로 이 구조를 선택하였습니다:
- Kubernetes StatefulSet을 활용하면 단일 노드로의 전환이 쉬움
- 프로덕션 환경에서는 서비스의 고가용성(High Availability), 성능 안정성(Performance Stability)을 위해 데이터베이스 이중화가 필수적임
2.1.4 Caching
각 서비스의 읽기 성능 향상을 위해 Redis를 활용한 캐싱 전략을 도입하였습니다. 백엔드 서비스와 데이터베이스 사이에 Redis를 두어, 데이터베이스 접근이 필요한 클라이언트의 요청 시 다음과 같은 프로세스로 동작하도록 설계하였습니다:
- 데이터베이스 읽기 작업 발생 시 (Cache-Aside)
- Redis에서 먼저 데이터 존재 여부 확인
- Cache Hit: 즉시 캐시된 데이터 반환
- Cache Miss: 데이터베이스에서 데이터를 조회하여 반환하고, Redis에도 저장
- 데이터베이스 쓰기 작업 발생 시
- 쓰기 작업에 대하여 데이터베이스에 반영
- 해당 데이터와 관련된 캐시 키를 삭제(무효화)
이러한 캐싱 전략 도입을 통해 다음과 같은 이점을 얻고자 하였습니다:
- 읽기 성능 향상
- 데이터베이스 부하 감소
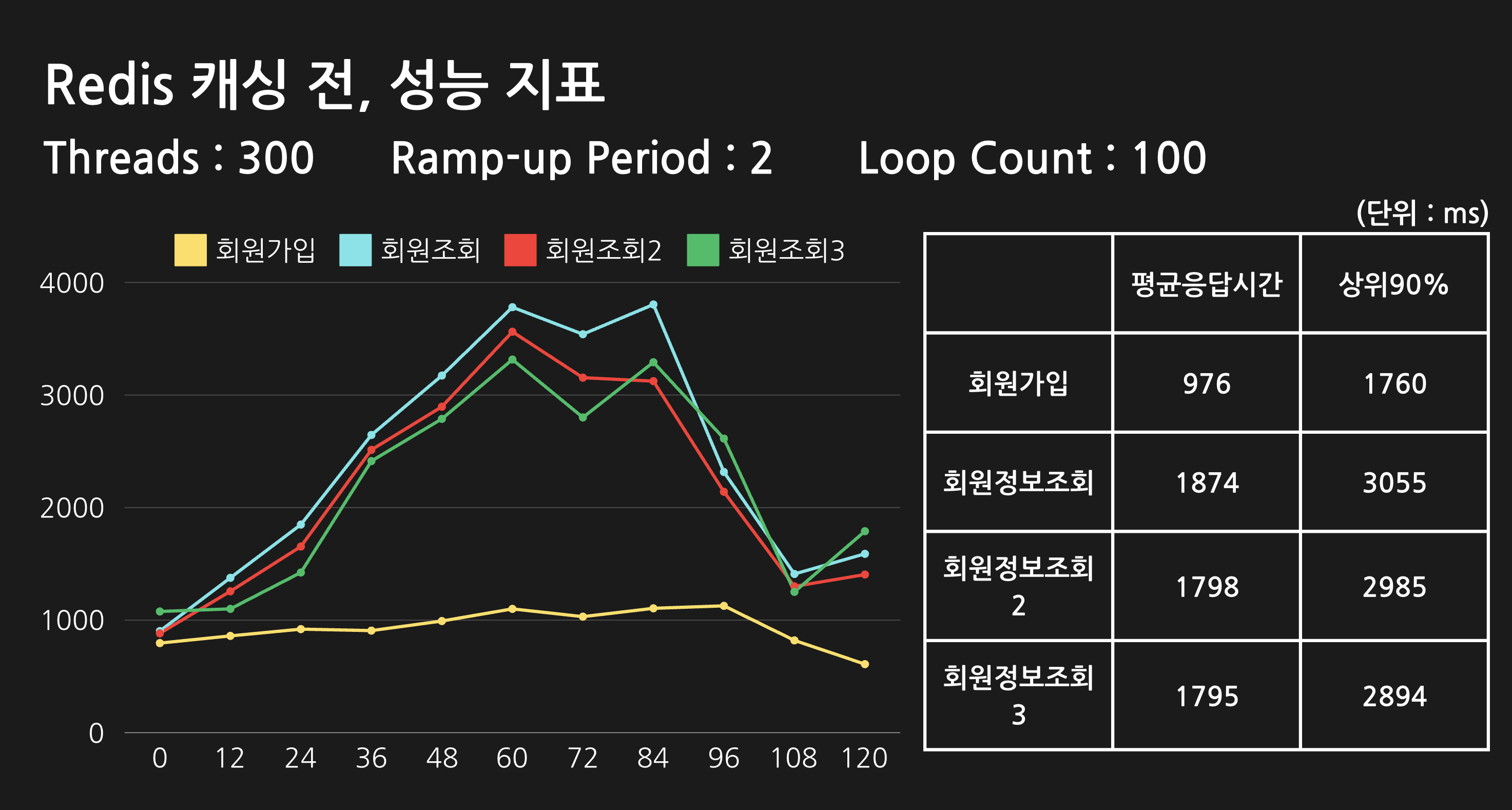
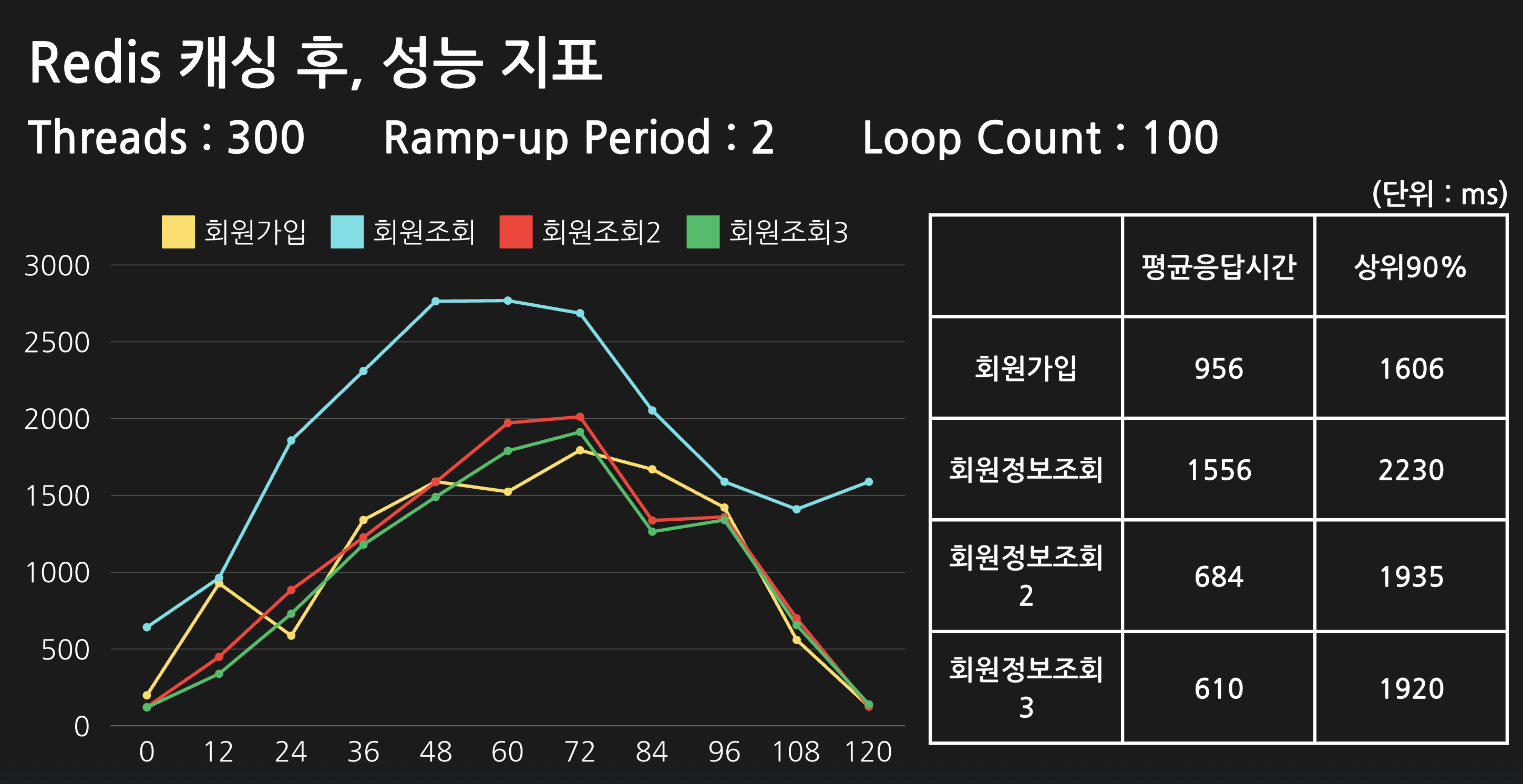
또한, 실제로 읽기 성능이 향상되었는지 확인하기 위해 성능 테스트도 진행해 보았으며, 성능 테스트 환경과 그 결과는 다음과 같습니다:
테스트 환경
- 테스트 도구: Apache JMeter
- 테스트 대상: AWS 쿠버네티스 클러스터에 배포된 API 엔드포인트
- 테스트 클라이언트: 로컬 환경 (MacBook Pro M2)
테스트 방식
- 캐싱 적용/미적용 버전의 API 서버를 동일 클러스터에 배포
- JMeter 설정 통일 (Number of Threads, Ramp-up Period, Loop Count)
- 각 버전의 Response Time 측정 및 비교
성능 테스트 결과
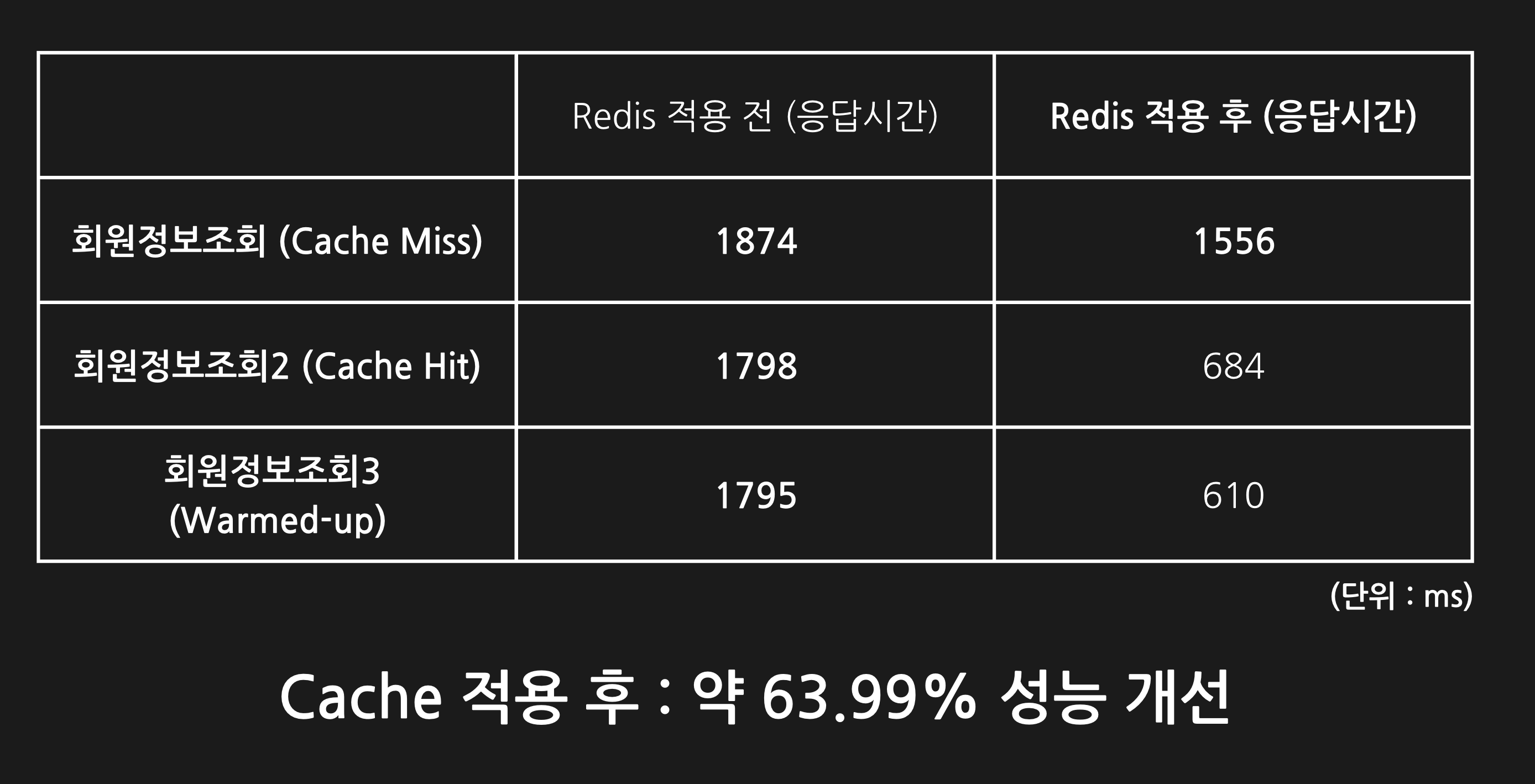
하지만, 이 프로젝트에서 제가 설계한 캐싱 전략은 대단히 잘못된 접근이라고 생각합니다. 그 이유를 설명하기에 앞서, 먼저 캐싱 도입 시 고려해야 할 사항과 캐싱을 사용하면 생길 수 있는 문제점을 살펴보겠습니다:
캐싱을 도입하기 전에 검토해야 할 사항
- 해당 데이터의 요청이 얼마나 자주 발생하는지
- 해당 데이터의 변경보다 조회가 더 많은지
- 해당 데이터 일관성이 얼마나 중요한지
- 어떤 캐시 저장소를 사용할지 (Redis, Memcached 등)
캐싱을 사용하면 생길 수 있는 문제점
- 데이터 일관성 유지가 어려움
- 전체 시스템 복잡도와 관리 비용 증가
- 캐시 미스(Cache Miss) 발생 시 오히려 성능 저하
- 캐시 서버가 Single Point of Failure(단일 장애 지점)가 될 수 있음
저는 이러한 고려 사항과 문제점을 전혀 생각하지 않고, 단순히 ‘읽기 성능 향상’과 ‘데이터베이스 부하 감소’라는 장점만 보고 캐싱을 적용했습니다. 이는 기술 도입에 있어 매우 잘못된 판단이었으며, 다시는 이러한 설계를 해서는 안 된다고 생각합니다.
이번 경험을 통해 새로운 기술을 도입할 때는 고려 사항과 발생할 수 있는 문제점을 꼼꼼히 검토해야 한다는 것을 배웠으며, 이러한 조건을 모두 고려한 캐싱 전략 설계는 앞으로 제가 해결해야 할 과제라고 생각합니다.
2.1.5 Event-Driven Architecture
이번 프로젝트에서 RAG 기반 레시피 추천 요청 API에 Event-Driven Architecture를 적용했습니다.
기존 레시피 추천 로직은 다음과 같았습니다:
- 사용자가 레시피 추천 API 호출
- Edge Service가 요청을 받아 Ingredients Manage Service로 전달
- Ingredients Manage Service가 냉장고 재료 정보를 AI Service로 전달
- AI Service가 레시피 추천 결과 반환
이 과정에서 AI Service가 레시피를 추천하는 데 몇 초의 시간이 걸렸고, 이에 따라 사용자가 오래 기다려야 할 뿐만 아니라, AI Service의 지연이 다른 서비스에도 영향을 미칠 수 있다는 문제가 있었습니다.
이 문제를 해결하기 위해 레시피 추천 요청을 비동기로 처리했습니다. 사용자는 레시피 추천 요청 후 바로 다른 작업을 할 수 있고, 추천 결과가 나오면 이를 전달받는 방식입니다. 이를 위해 pub/sub 구조를 도입했고, 구체적인 흐름은 다음과 같습니다:
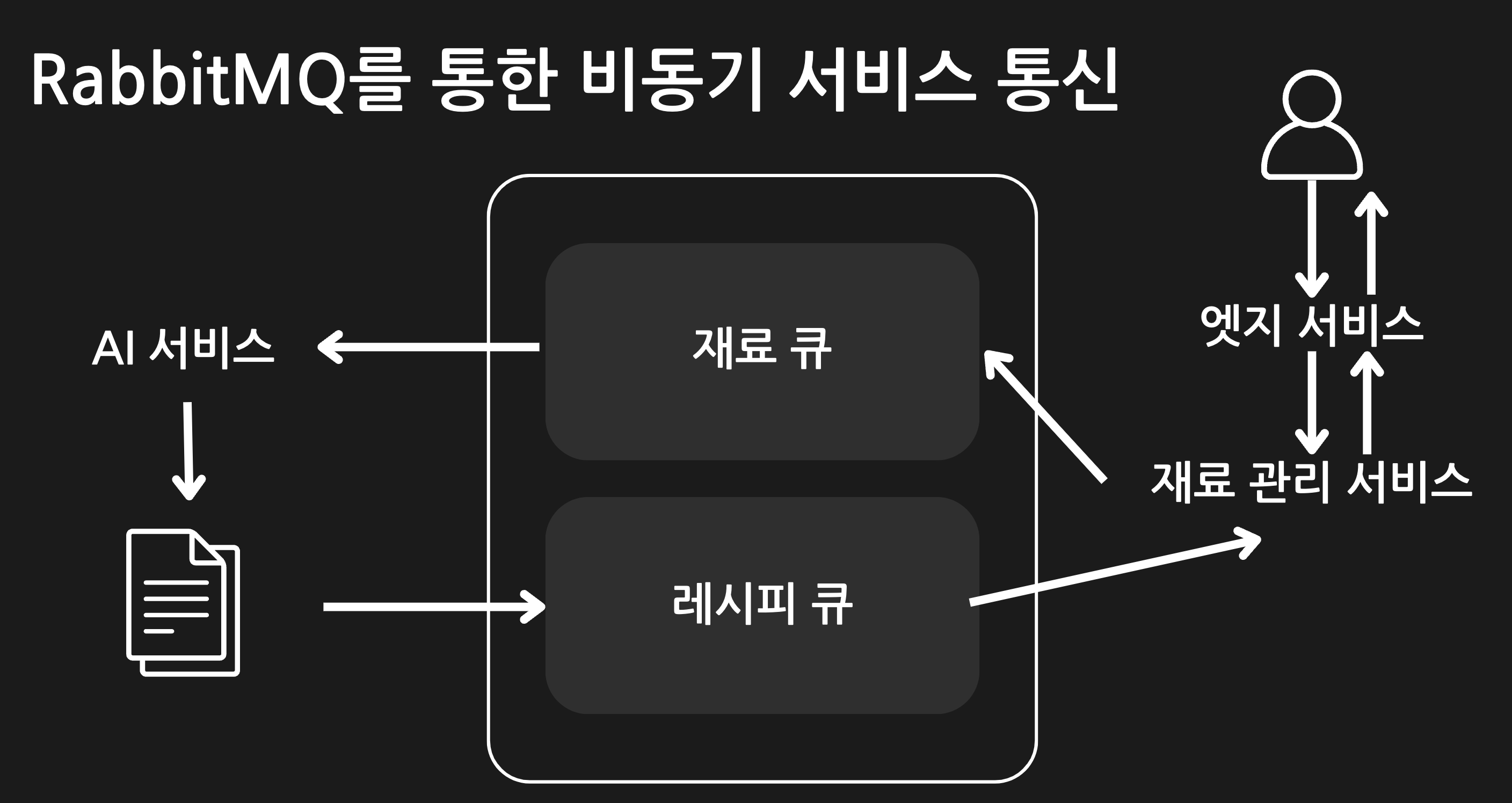
메시지 큐로는 RabbitMQ를 선택했습니다. Kafka도 고려했지만, 다음과 같은 이유로 RabbitMQ를 선택했습니다:
- 구현과 운영이 Kafka에 비해 비교적 간단함
- 구현 초기 단계이기 때문에 트래픽이 많지 않아 Kafka는 과도한 선택이라고 판단함
이러한 Event-Driven Architecture 적용으로 다음과 같은 장단점이 있었습니다:
장점
- 서비스 간 결합도가 감소하여 Failure Tolerance 증가
- 서비스 간 결합도가 감소하여 각 서비스가 독립적으로 Scale-out 가능
- 오래 걸리는 요청을 비동기 처리로 바꿔 사용자 경험을 개선할 수 있음
- 메시지 큐가 버퍼 역할을 하여 트래픽 급증 시에도 안정적인 처리가 가능
단점
- 메시지 큐 도입으로 인한 시스템 구조가 복잡해져 운영 관리가 어려워짐
- 비동기 처리 방식으로 인해 메시지 순서 보장이 어려워, 장애 발생 시 문제 추적과 디버깅이 까다로움
이러한 단점이 있지만, AI Service의 긴 응답 시간으로 인한 사용자 경험 저하 문제를 해결하고 서비스 간의 독립성을 높이는 것이 더 중요하다고 판단하여 Event-Driven Architecture를 도입했습니다. 다만, 비동기 처리로 인한 메시지 추적과 디버깅 문제는 앞으로 해결해야 할 과제라고 생각합니다.
2.1.6 Configuration Management
클라우드 네이티브 애플리케이션을 구축하기 위해 MSA(Micro Service Architecture)를 채택하였고, 각 서비스의 설정 파일을 관리하기 위해 설정 외부화 패턴(configuration externalization pattern)을 고려하게 되었습니다.
먼저 설정 파일을 외부화하지 않았을 경우 발생하는 문제점은 다음과 같습니다:
- 설정 변경 시 애플리케이션 전체를 다시 빌드하고 배포해야 함
- API Key나 데이터베이스 접속 정보와 같은 민감한 정보가 애플리케이션 패키지에 포함되어 보안에 취약함
이러한 문제점을 해결하기 위해 설정 외부화 패턴(configuration externalization pattern)을 도입하였고, 이에 따라 다음과 같은 추가 요구사항이 발생하였습니다.:
- 설정 데이터의 지속성, 버전관리, 접근 제어가 필요하다.
- 민감한 정보를 안전하게 저장해야 한다.
- 애플리케이션 인스턴수 증가 시, 각 인스턴스에 대해 분산된 방식으로 설정을 처리해야 한다.
- 설정 데이터 변경 후, 애플리케이션을 다시 시작하지 않고 런타임에 읽을 수 있도록해야 한다.
이러한 요구사항을 만족시키기 위해 중앙 집중식 설정 관리가 필요했고, Spring 기반 애플리케이션에서 가장 보편적으로 사용되는 Spring Cloud Config Server를 사용해 구현하도록 설계하였습니다.
이때 Spring Cloud Config Server를 사용하게 되면 다음과 같은 단점이 있습니다:
단점
- 설정 서버 도입으로 인한 시스템 복잡도 증가
- 설정 서버 도입으로 인한 관리 비용 증가
- 설정 서버에 장애가 생기면 다른 모든 애플리케이션이 시작할 수 없어 단일 장애 지점(Single Point of Failure)이 될 수 있음
단일 장애 지점 문제는 쿠버네티스의 ReplicaSet을 통해 해결 가능하다고 판단했습니다. 설정 서버 도입으로 인한 시스템 복잡도 증가와 관리 비용 증가는 불가피하지만, 앞서 언급한 요구사항을 모두 충족하는 것이 더 중요하다고 판단했습니다.
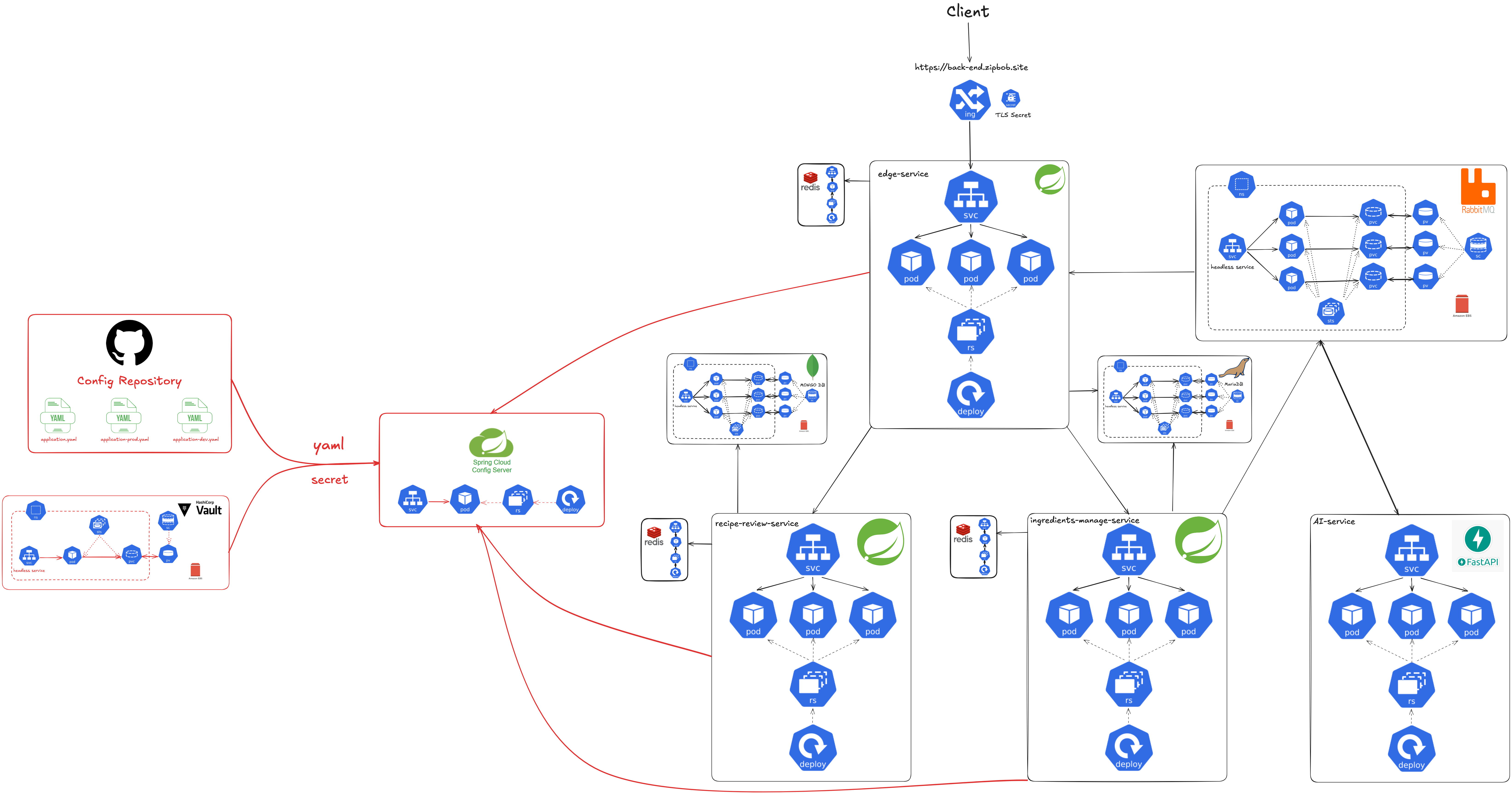
먼저 1, 2, 3번 요구사항을 만족시키기 위한 해결 방안은 다음과 같으며, 이를 그림으로 나타내면 다음과 같습니다:
- 모든 애플리케이션의 설정 데이터를 Github Repository에 저장하여 설정 데이터에 대한 지속성, 버전관리, 액세스 제어를 제공한다.
- Hashicorp Vault를 사용하여 설정 데이터의 민감한 정보를 안전하게 저장한다.
- Spring Cloud Config Server의 기능을 활용해, 각 애플리케이션 인스턴스가 설정 데이터 요청 시, 중앙 설정 서버는 민감하지 않은 데이터는 Github Repository에서, 민감한 데이터는 Hashicorp Vault에서 가져와 각 애플리케이션 인스턴스에게 전달한다.
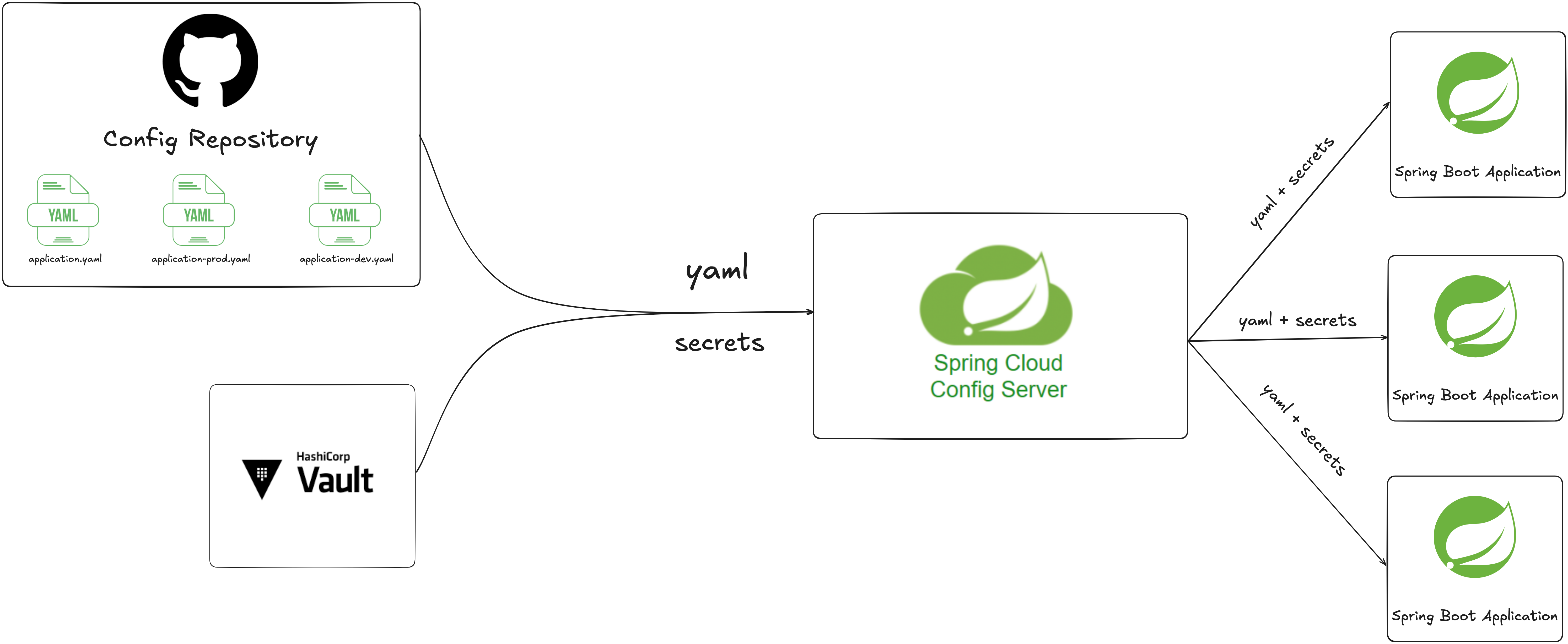
다음으로 4번 요구사항을 만족시키기 위해 설정 데이터의 변경을 Github Repository에 반영하면 애플리케이션 런타임에 설정 정보를 동적으로 변경하는 파이프라인을 설계하였으며, 이를 그림으로 나타내면 다음과 같습니다.
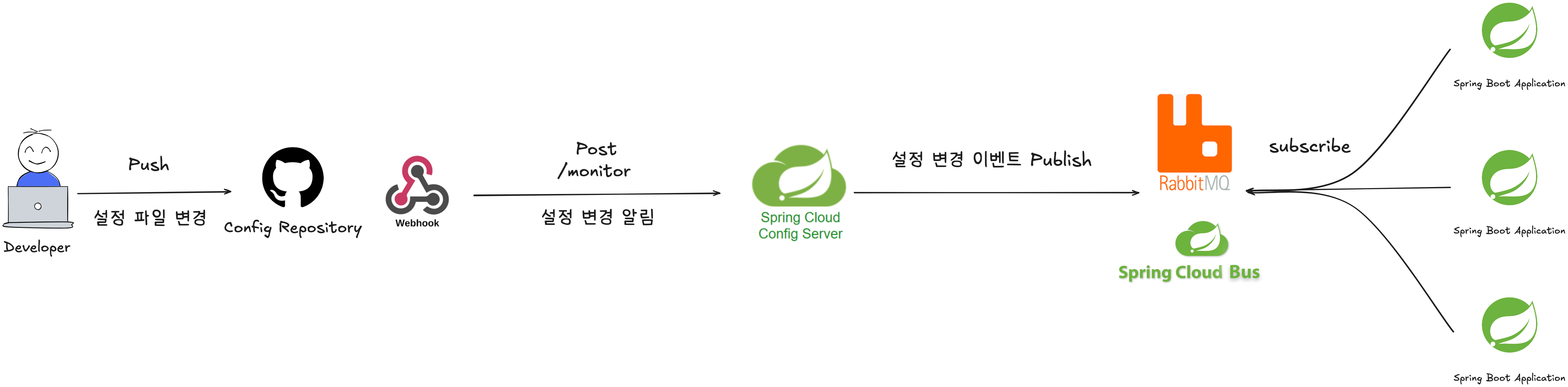
2.2 Deployment Architecture
ZipBob 프로젝트의 전체 시스템은 쿠버네티스 클러스터 위에서 동작합니다. Spring 애플리케이션은 Cloud Native Buildpacks을 통해 컨테이너 이미지로 패키징되며, 데이터 서비스 및 Vault 등 그 외의 서비스도 쿠버네티스 오브젝트로 관리됩니다. 쿠버네티스를 사용한 이유는 다음과 같습니다:
- 애플리케이션을 컨테이너 이미지로 패키징하면 클러스터의 서버 스펙과 관계없이 동일한 실행 환경을 보장할 수 있다.
- 쿠버네티스가 자동으로 컴퓨팅 리소스를 모니터링하고 리소스가 충분한 노드에 애플리케이션을 배포하여 유지보수성이 향상됨
- 각 서비스의 전체 생명주기를 선언적 코드로 관리할 수 있다.
- 각 서비스의 상태를 자동으로 확인(Health Check)하고 자가 치유(Self-Healing)를 할 수 있다.
- 수평적 확장(Horizontal Scaling)이 쉬우며, 트래픽에 따라 오토스케일링(Auto Scaling)을 하도록 구현할 수 있다.
- 애플리케이션의 개발 환경과 운영 환경을 동일하게 유지할 수 있다.
- 서비스 디스커버리(Service Discovery)와 로드밸런싱(Load Balancing)을 쉽게 구현할 수 있다.
물론 쿠버네티스 도입에는 추가적인 인프라 비용과 관련 기술 학습이 필요하지만, 앞서 언급한 이유를 고려한다면 충분히 도입할 가치가 있다고 생각했습니다.
전체 구현 내용은
zipbob-deployment리포지터리에서 확인하실 수 있습니다.
2.2.1 State vs Stateless
쿠버네티스를 사용하면 애플리케이션의 Scale-In/Out이 매우 쉬워집니다. 이러한 수평적 확장을 보장하기 위해 애플리케이션은 상태를 갖지 않는 프로세스(stateless process)가 되도록 설계하고 아무것도 공유하지 않는 아키텍처(share-nothing architecture)가 되도록 해야 합니다. 즉, 애플리케이션 인스턴스 간에 상태를 공유해서는 안 되며, 상태 공유는 데이터 서비스(MariaDb, MongoDB, Redis 등)를 통해 이루어져야 합니다.
이를 쿠버네티스에서 구현하기 위해 다음과 같이 설계하였습니다.
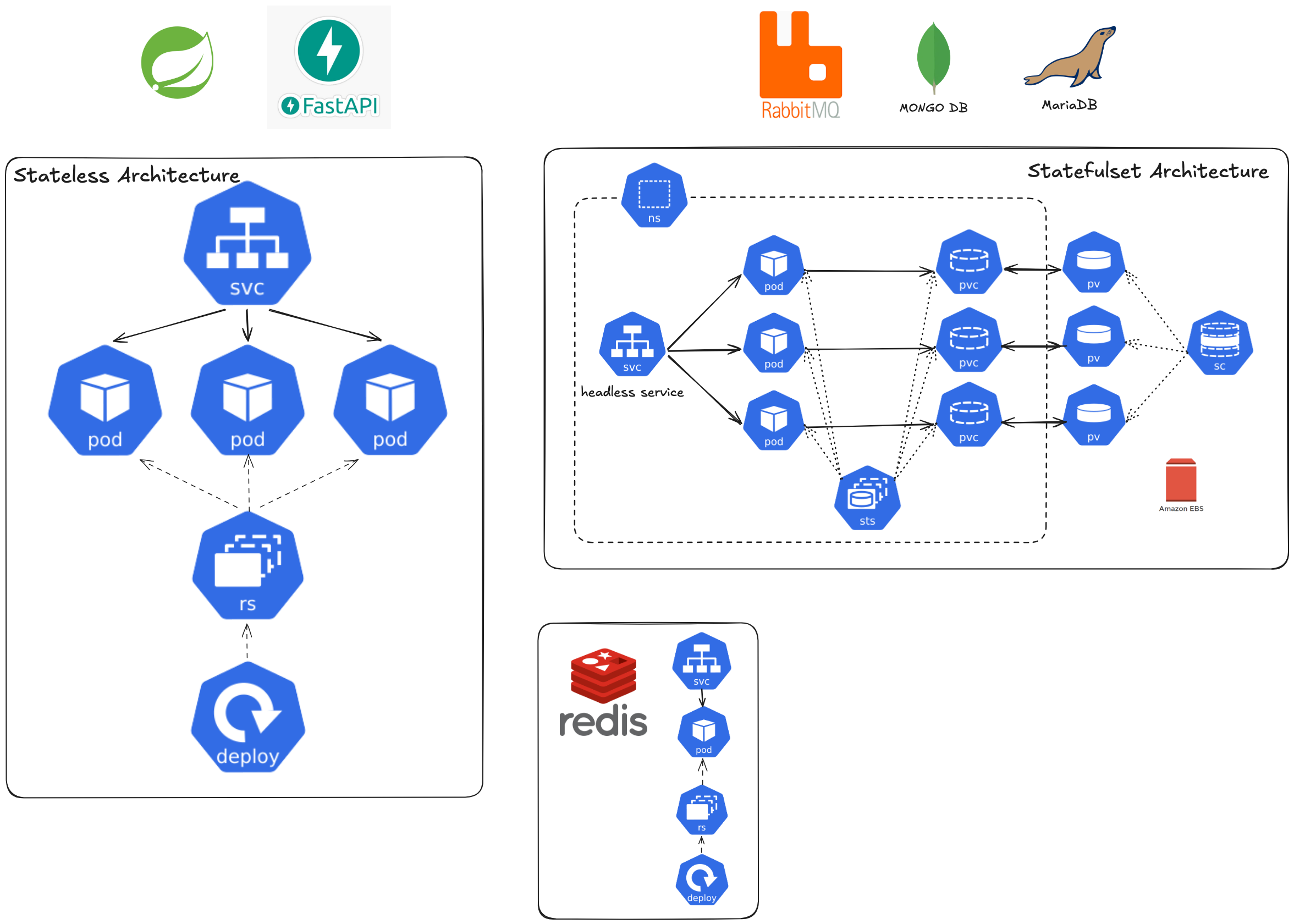
상태를 갖지 않는 서비스는 Kubernetes의 Deployment 오브젝트로, 상태를 갖는 서비스는 StatefulSet 오브젝트로 구현하였습니다. 구체적인 구현 내용은 다음과 같습니다:
Stateless Architecture
- 상태를 갖지 않도록 Application Code를 작성하여 컨테이너 이미지로 패키징
- 컨테이너 이미지를 Pod단위로 실행하며 ReplicaSet을 통해 Pod 수를 조절
- Deployment를 통해 애플리케이션 배포 및 관리
- ClusterIP 타입 Service로 서비스 디스커버리와 로드밸런싱 제공
Stateful Architecture
- StatefulSet를 통해 구현
- Vault를 제외한 데이터 서비스는 StorageClass를 통한 동적 프로비저닝으로 스토리지 할당
- Standalone 모드의 Vault는 정적 프로비저닝(PV, PVC) 으로 스토리지 할당
- AWS EBS를 스토리지로 사용
- Headless Service로 각 Pod에 접근할 수 있도록 함
저희 프로젝트의 Stateless 서비스로는 Spring Application, AI Service, Redis가 있으며, Stateful 서비스로는 Vault, MariaDB, MongoDB, RabbitMQ가 있습니다. Redis의 경우 Refresh Token 저장소와 데이터베이스 캐시로 사용되지만, Refresh Token은 사용자가 로그인을 다시 하면 재발급이 가능하고 캐시는 일시적인 성능 향상을 위한 것이므로 데이터 영속성보다는 빠른 복구가 중요하다고 판단하여 Deployment로 구현하였습니다.
2.2.2 ingress controller & edge service
지금부터 쿠버네티스 클러스터에 배포된 Deployment Architecture에 대하여 하나씩 살펴보겠습니다. 클라이언트의 모든 요청은 Ingress Controller에서 처리되며, 쿠버네티스 Secret으로 관리되는 인증서를 통해 TLS 연결을 수립합니다. 이후 요청은 Edge Service로 전달되고, 내부 통신은 HTTP 프로토콜을 사용합니다. Edge Service에서는 전달받은 요청에 대한 인증/인가(Authentication/Authorization)를 처리합니다.
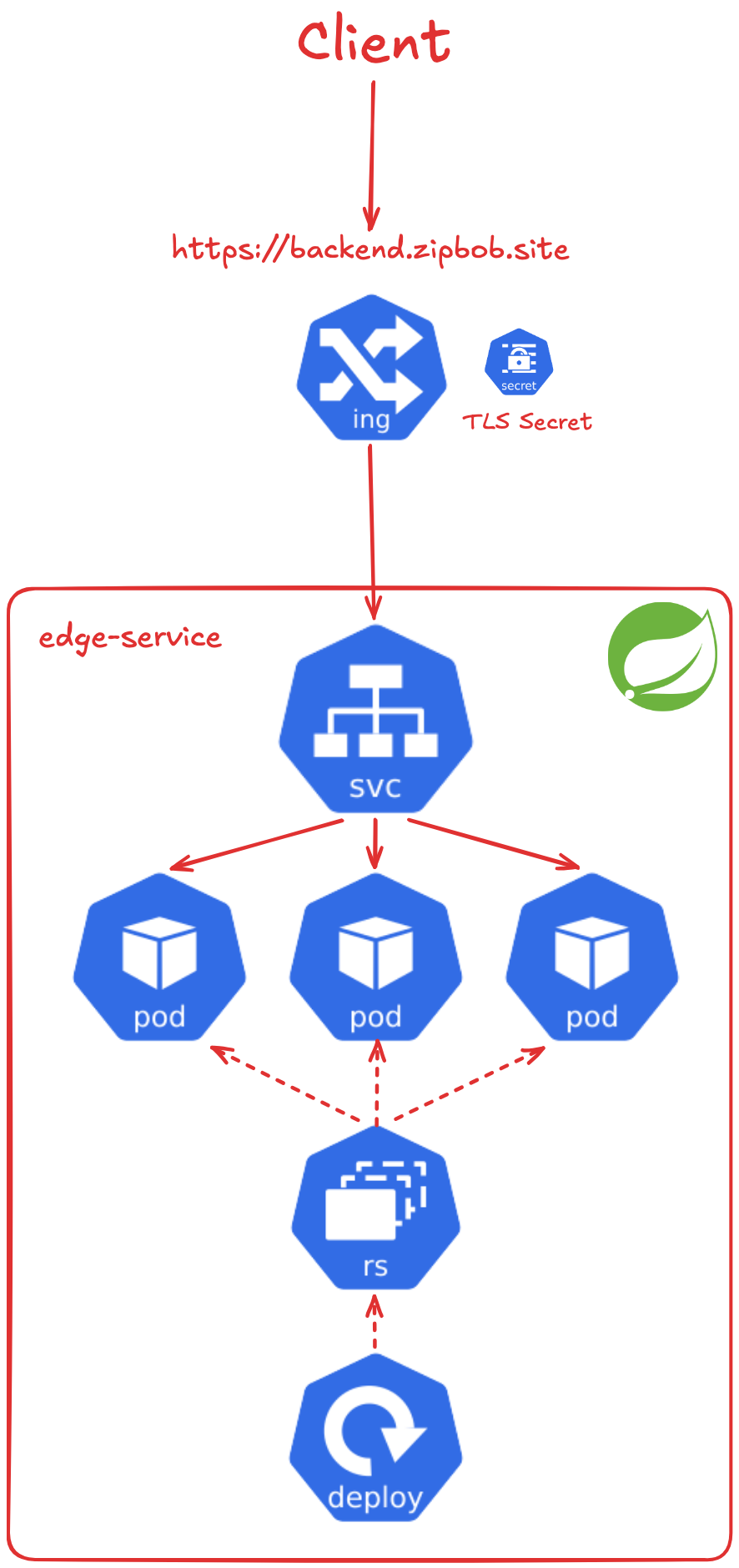
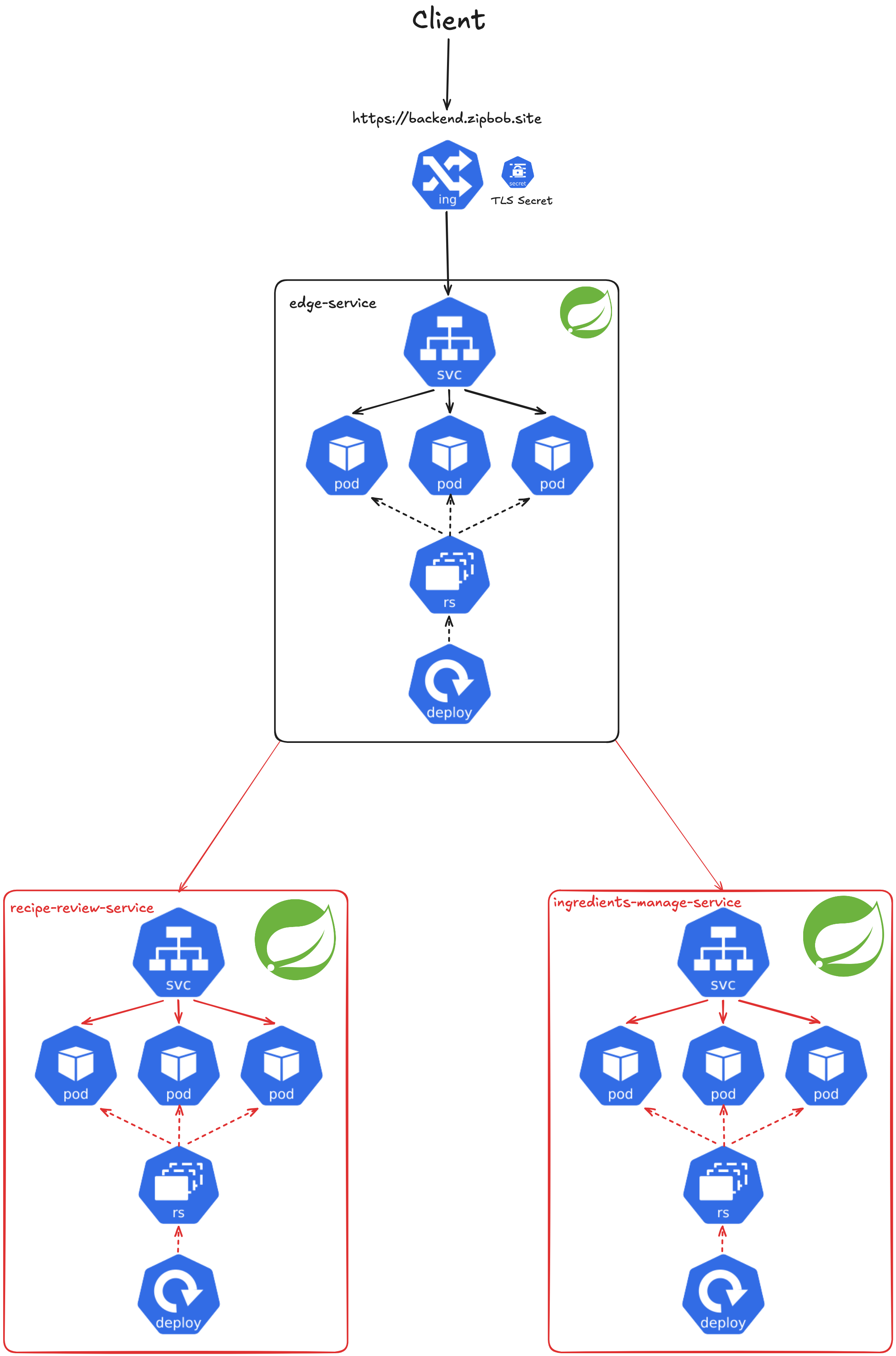
2.2.3 Request Routing
Edge Service에서는 인증된 요청을 적절한 서비스로 라우팅합니다. Spring Cloud Gateway를 사용하여 라우팅을 구현했으며, 각 요청은 URL 패턴에 따라 해당하는 서비스로 전달됩니다. 예를 들어 /ingredients/** 패턴의 요청은 Ingredients Manage Service로, /reviews/** 패턴의 요청은 Recipe Review Service로 전달됩니다.
2.2.4 AI Service
FastAPI로 구현된 AI Service는 사용자의 식재료 정보를 기반으로 레시피를 추천합니다. AI Service의 긴 처리 시간을 고려하여 Event-Driven Architecture를 적용했으며, RabbitMQ를 메시지 브로커로 사용하여 Ingredients Manage Service와 AI Service 간의 비동기 통신이 적용된 구조입니다.
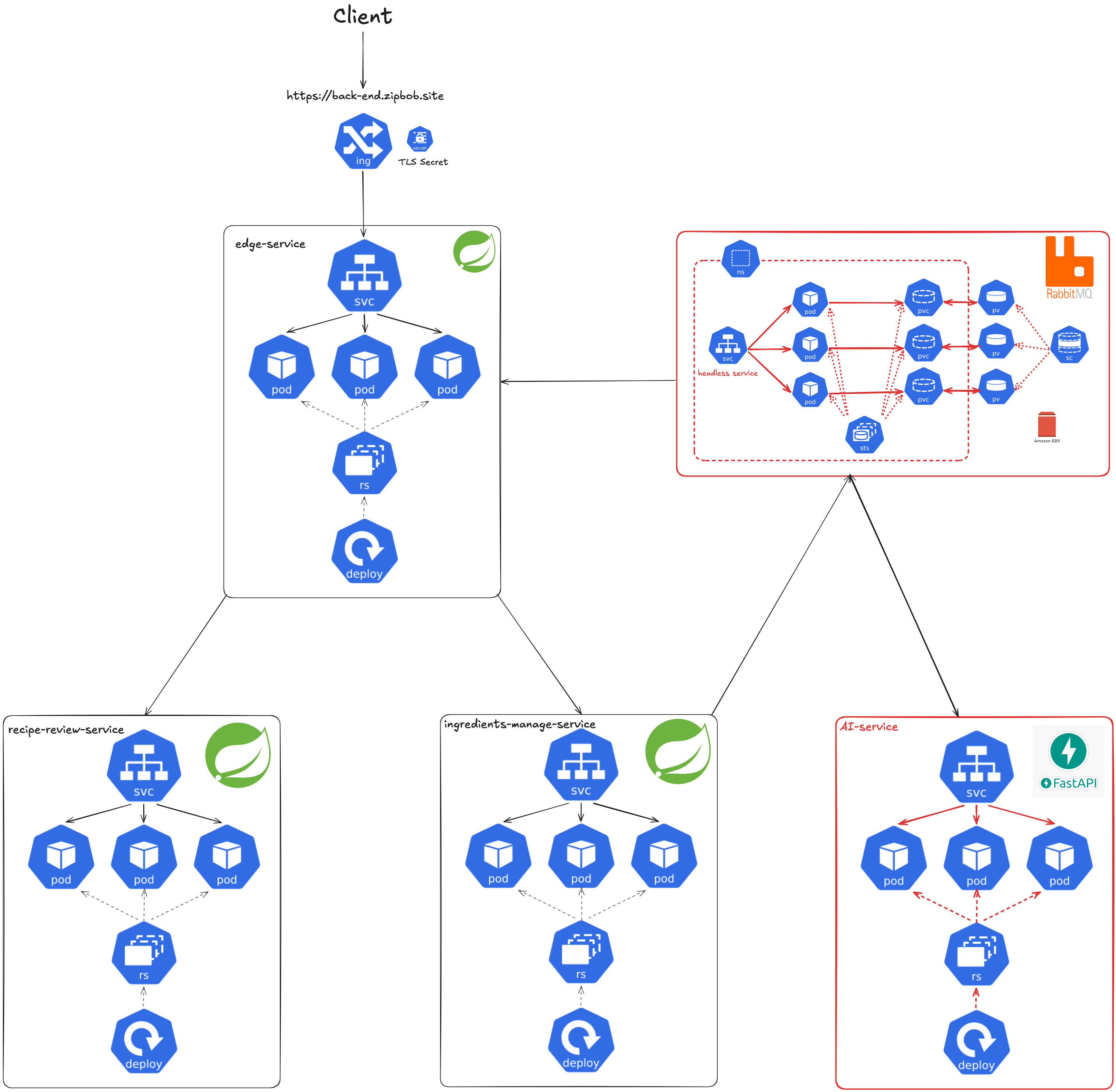
2.2.5 Database
데이터베이스는 MariaDB와 MongoDB를 사용했으며, 각각 StatefulSet으로 배포해 서비스와 연결했습니다. Master-Slave 구조를 적용하였으며, 스토리지는 AWS EBS를 사용했습니다. StatefulSet 구성을 위한 매니페스트 파일과 데이터베이스 설정을 직접 작성하여 배포했습니다.
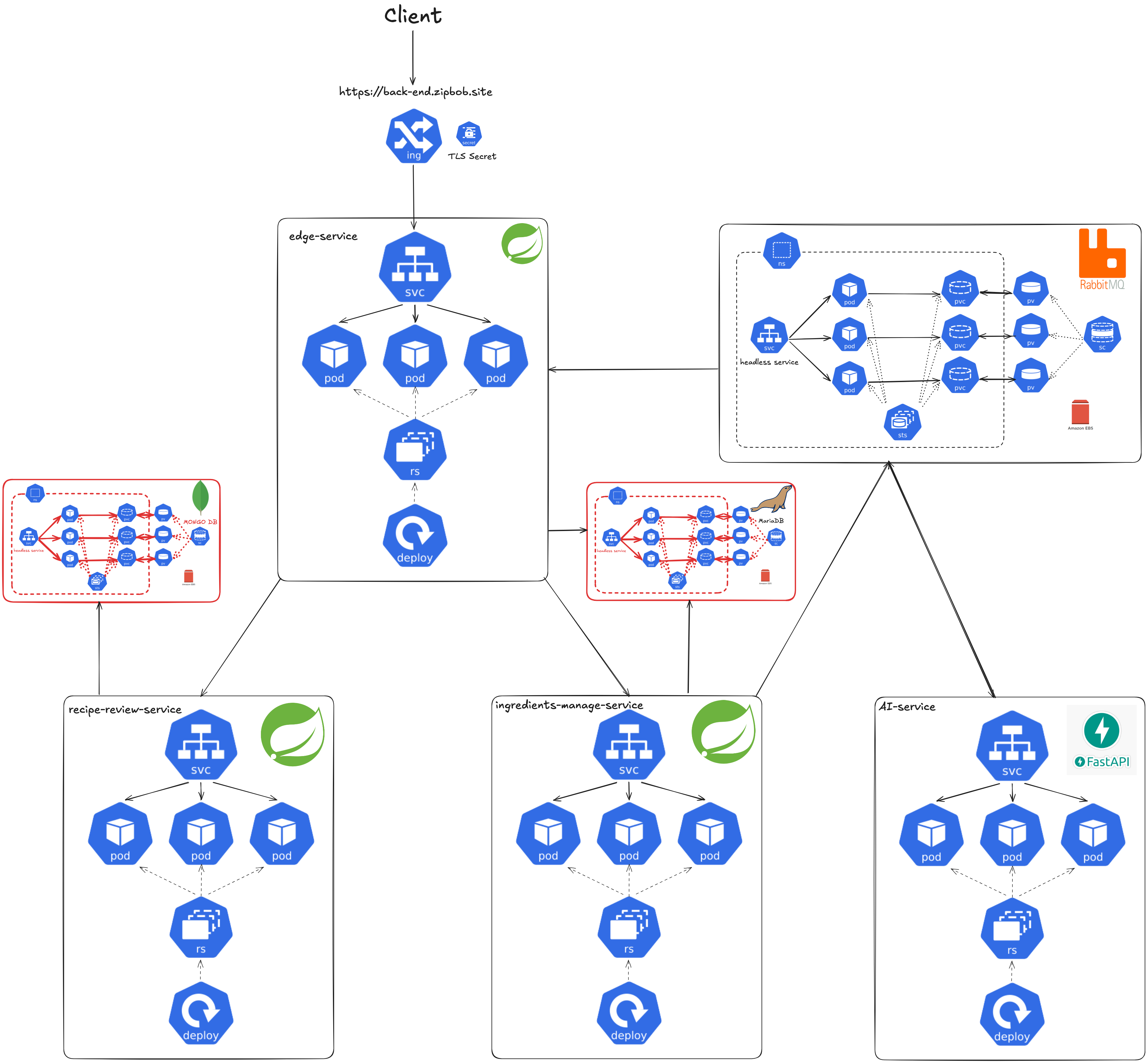
2.2.6 Redis
Edge Service, Ingredients Manage Service, Recipe Review Service에서 사용하는 Redis를 각각 별도의 Deployment로 배포했습니다. 2.2.1 State vs Stateless에서 설명했듯이 데이터 영속성보다는 빠른 복구가 중요하다고 판단했기 때문에 StatefulSet이 아닌 Deployment로 구현했습니다. Redis의 각 Deployment는 단일 Pod로 구성했으며, 필요한 쿠버네티스 매니페스트도 직접 작성해서 배포했습니다.
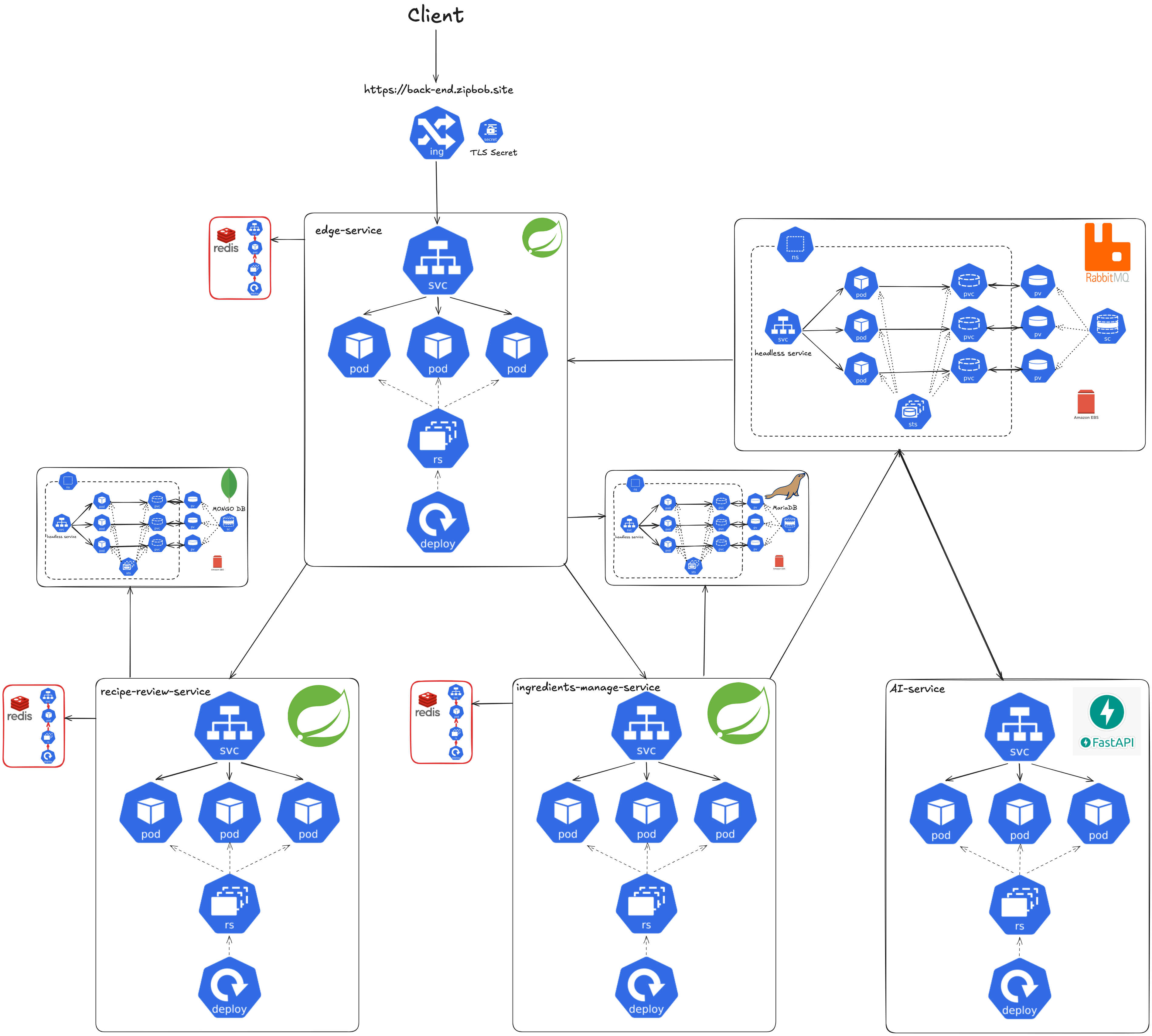
2.2.7 Config Service
마지막으로 Application이 실행하는 시점에 설정 데이터를 제공해 주는 Config Service를 포함한 전체 Deployment Architecture입니다. 설정 데이터는 Github Repository에서 관리하였고, 민감한 데이터는 Hashicorp Vault를 사용하여 관리했습니다. Vault는 Hashicorp에서 제공하는 Helm Chart를 사용하였고, 스토리지와 실행 모드(standalone) 등의 설정을 ZipBob 프로젝트에 맞게 수정하여 적용했습니다.
2.3 DevOps
저는 DevOps가 실제 서비스를 개발하고 운영하기 위해 개발자와 운영자가 효율적으로 협업하여 빠르고 안정적인 소프트웨어를 제공하기 위한 문화라고 생각합니다. 이번 프로젝트에서 저는 개발자보다 운영자에 가까운 역할을 맡아, 지금까지 설계된 아키텍처를 기반으로 서비스를 개발하고 운영하기 위해 필요한 환경을 구축하였습니다. 이번 파트에서는 제가 이 환경을 왜 구축했고, 어떻게 구축했는지에 대하여 설명하겠습니다.
2.3.1 개발 환경 구축
백엔드 개발자가 최대한 애플리케이션 코드의 비즈니스 로직을 작성하는 데만 집중할 수 있도록 개발 환경을 구축하였습니다. 이를 위해 다음과 같은 부분을 고려해야 했습니다.
- 개발 환경은 운영 환경과 최대한 동일하게 구성해야 한다.
- 개발자가 로컬에서 작성한 코드를 운영 환경과 유사한 환경에서 즉시 테스트할 수 있어야 한다.
- 운영 환경의 쿠버네티스 사용에 따른 비용 부담을 고려해 개발 환경은 최소 비용으로 구성해야 한다.
- 개발 환경 구성을 언제든 쉽게 변경할 수 있고, 개발자가 필요에 따라 직접 설정을 조정할 수 있어야 한다.
이러한 점을 고려하여 Docker Compose를 사용해 개발 환경을 구축하였습니다. Docker Compose를 사용하여 개발 환경을 구축했을 때의 장점은 다음과 같습니다:
- 운영 환경의 컨테이너 이미지를 그대로 활용해 개발 환경과 운영 환경을 최대한 동일하게 구성할 수 있다.
- 한 줄의 명령어(docker compose up)로 개발 환경을 빠르게 구성하고 localhost를 통해 각 인프라 요소에 쉽게 접근할 수 있다.
- Docker Desktop을 사용해 무료로 개발 환경을 구축할 수 있다.
- 하나의 코드 파일로 전체 환경을 관리할 수 있어 구성 환경에 대하여 쉽게 변경할 수 있고 개발자가 필요에 따라 직접 설정을 조정할 수 있다.
이러한 이유로 Docker Compose를 사용해 개발 환경을 구축하였으며, Docker Compose 파일과 실행 방법에 대한 설명도 함께 작성하여 제공했습니다. 자세한 내용은 zipbob-deployment/docker 리포지터리에서 확인하실 수 있습니다.
하지만 실제 운영 환경에서는 Kubernetes를 사용하였으며, Docker Compose와 Kubernetes 간 차이는 분명히 존재합니다. 이를 고려해 Docker Desktop을 통해 단일 노드 Kubernetes 클러스터를 구성할 수 있도록 매니페스트 파일과 실행 스크립트를 작성했으며 실행 방법에 대한 설명서도 제공하였습니다. 관련 내용은 zipbob-deployment/k8s 리포지터리에서 확인하실 수 있습니다.
2.3.2 쿠버네티스 클러스터 구축
운영 환경을 위한 클라우드로 가장 보편적인 AWS를 선택했습니다. AWS에서 쿠버네티스 클러스터를 구성하는 방법이 여러 가지가 있지만, 그 중 다음 세 가지 방식을 비교해 봤습니다:
- Kubeadm
- AWS EKS(Elastic Kubernetes Service)
- kOps
Kubeadm은 VPC, EC2, IAM 같은 AWS 리소스를 일일이 직접 구성해야 해서 AWS와 같은 클라우드 환경에서 사용하기에는 적합하지 않다고 생각합니다. EKS와 kOps 중에서는 EKS를 한 번도 사용해 보지 않았지만, kOps는 이전에 공부하면서 정리해 둔 자료가 있어서 kOps를 선택했습니다. 제가 정리한 kops로 AWS에서 쿠버네티스 설치 자료를 참고해서 클러스터를 구성했습니다.
실제로 kOps보다 EKS를 더 많이 쓰긴 하지만, 지금은 두 솔루션을 비교하는 것보다 하나를 제대로 구현해 보는 게 더 중요하다고 생각했습니다. 나중에 EKS나 GKE(Google Kubernetes Engine)같은 여러 가지 솔루션을 사용해 보면서 각 장단점을 비교해 보는 건 제가 앞으로 해결해야 할 과제라고 생각합니다.
2.3.3 CI/CD 파이프라인 구축
백엔드 개발이 어느정도 완료되면서, 실제 쿠버네티스 클러스터에 서비스를 배포하기 시작했습니다. 이때 코드 변경 사항을 운영 환경에 반영하기 위해 다음과 같은 단계를 거쳐야 했습니다:
- 로컬에서 애플리케이션 빌드 및 테스트
- GitHub에 코드 변경 사항 Push
- 코드 리뷰가 끝난 후 배포 브랜치에 merge
- 로컬에서 컨테이너 이미지로 패키징
- 이미지를 Container Registry에 Push
- 클러스터에 직접 접속하여 명령어(kubectl)로 배포
이러한 많은 작업을 수동으로 진행하는 것은 매우 비효율적이며, 실수 위험도 크기 때문에 코드 변경 사항 push부터 배포까지의 모든 과정을 자동화하기 위해 GitHub Actions과 ArgoCD를 사용해 CI/CD 파이프라인을 구축하게 되었습니다.
CI(Continuous Integration) 과정에서는 다음과 같은 작업을 수행합니다:
- 개발 브랜치에 코드 변경 사항 Push
- GitHub Actions에서 빌드 및 테스트 실행
- Anchore를 통한 보안 취약점 스캔
- 코드 리뷰가 끝난 후 배포 브랜치에 Merge
- Cloud Native Buildpacks으로 컨테이너 이미지 패키징
- GitHub Container Registry에 이미지 Push
- 새 이미지 버전을 쿠버네티스 매니페스트 저장소에 반영
이러한 CI 과정이 성공적으로 진행되면, 다음과 같은 CD(Continuous Delivery) 과정이 진행됩니다:
- ArgoCD는 쿠버네티스 매니페스트 저장소를 모니터링
- 변경 사항 감지
- 수정된 이미지 버전을 쿠버네티스 클러스터에 적용
CI 도구로는 GitHub Actions를 선택했습니다. 이전에 Jenkins Piepline으로 구현해 본 적이 있지만, Jenkins는 별도의 설치가 필요하고 관련 플러그인을 수동으로 설치해야 하는 번거로움이 있었습니다. 반면 Github Actions을 활용하면 별도의 컴퓨팅 자원 없이도 CI 과정을 자동화할 수 있습니다. CI 과정의 구현 내용은 recipe-review-service/.github/workflows/commit-stage.yaml에서 확인할 수 있습니다.
지금까지 보시다시피 애플리케이션의 배포와 운영에 필요한 모든 요소를 Git으로 관리하는 GitOps 방식을 구현했습니다. 이러한 GitOps 전략에서 CD(Continuous Delivery)를 구현할 수 있는 도구는 여러 가지가 있지만 가장 보편적이고 많이 사용되는 ArgoCD를 선택했습니다. 여러 도구를 사용해 보고 비교해 보는 것도 좋지만, 지금은 사실상 업계 표준(de-facto standard)인 ArgoCD를 제대로 익히고 활용해 보는 게 더 중요하다고 생각했습니다.
2.3.4 Metrics Monitoring
서비스를 운영하기 위해 Metrics Monitoring은 필수적이라고 생각합니다. 이를 위해 Prometheus와 Grafana를 사용하여 Metircs Monitoring 시스템을 구축하였으며, Prometheus를 통해 두 가지의 중요한 메트릭을 수집할 수 있었습니다. 먼저 node-exporter를 DaemonSet으로 배포하여 각 노드의 CPU, 메모리 같은 하드웨어 메트릭을 수집했고, kube-state-metrics를 Deployment로 배포하여 Pod, Deployment 등 쿠버네티스 리소스의 상태 메트릭을 수집했습니다. 이렇게 수집된 메트릭 데이터를 시각화하기 위해 Grafana를 사용했습니다.
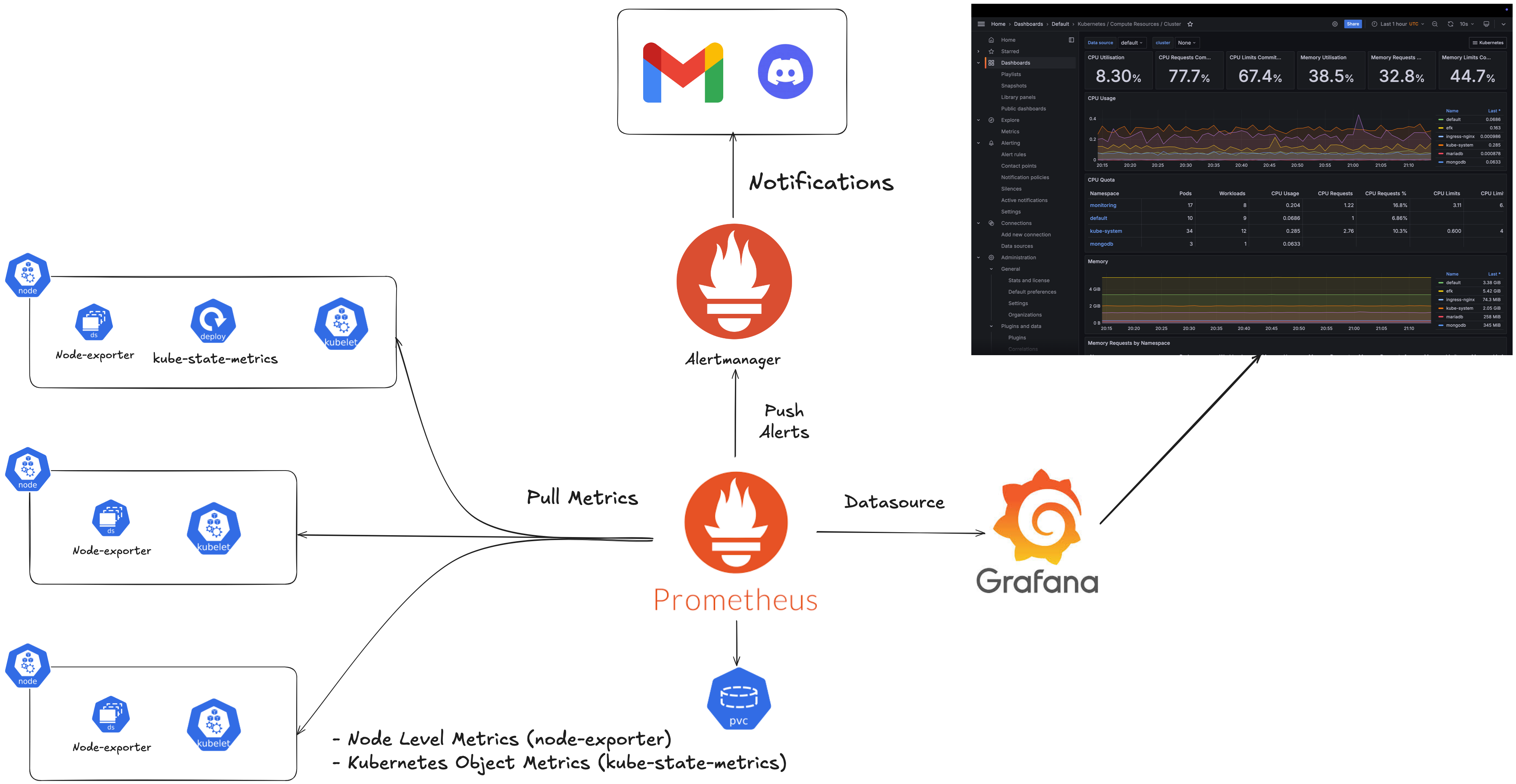
실제 트래픽을 받지는 않았지만, 수집된 메트릭 데이터를 통해 애플리케이션의 초기 리소스 요구사항을 파악할 수 있었습니다. 또한 마스터 노드의 경우, 기존 서버(c5.xlarge, 4vCPU/8GB)의 메모리 사용률이 높은 것을 확인하여 동일한 CPU 코어 수에 메모리가 2배인 서버(t3.xlarge, 4vCPU/16GB)로 변경할 수 있었습니다.
구현은 kube-prometheus 프로젝트를 참고하였으며, 기본 설정만 적용했습니다. 실제 트래픽이 발생하는 상황에서는 서비스의 특성에 맞는 메트릭을 추가로 수집하고, 모니터링 대시보드도 커스터마이징해야 합니다. 또한 Prometheus의 쿼리 언어인 ‘PromQL’을 활용한 메트릭 분석도 필요한데, 이는 앞으로 Metrics Monitoring 시스템을 구축하는 데 있어서 제가 더 공부해야 할 부분이라고 생각합니다.
2.3.5 Logging System
로깅 시스템을 구축하기 전에는, 운영 환경에 배포된 애플리케이션의 로그를 확인하기 위해 쿠버네티스 클러스터에 접속하여 kubectl logs 명령어로 터미널에서 로그를 확인해야 했습니다. 이는 가독성이 떨어질 뿐만 아니라, 쿠버네티스 CLI 사용이 익숙하지 않은 팀원들은 직접 로그를 확인하기 어려워 제가 매번 확인해 줘야 하는 불편함이 있었습니다. 이러한 문제를 해결하기 위해 EFK 스택(Elasticsearch, Fluentd, Kibana)을 사용하여 로깅 시스템을 구축했습니다.
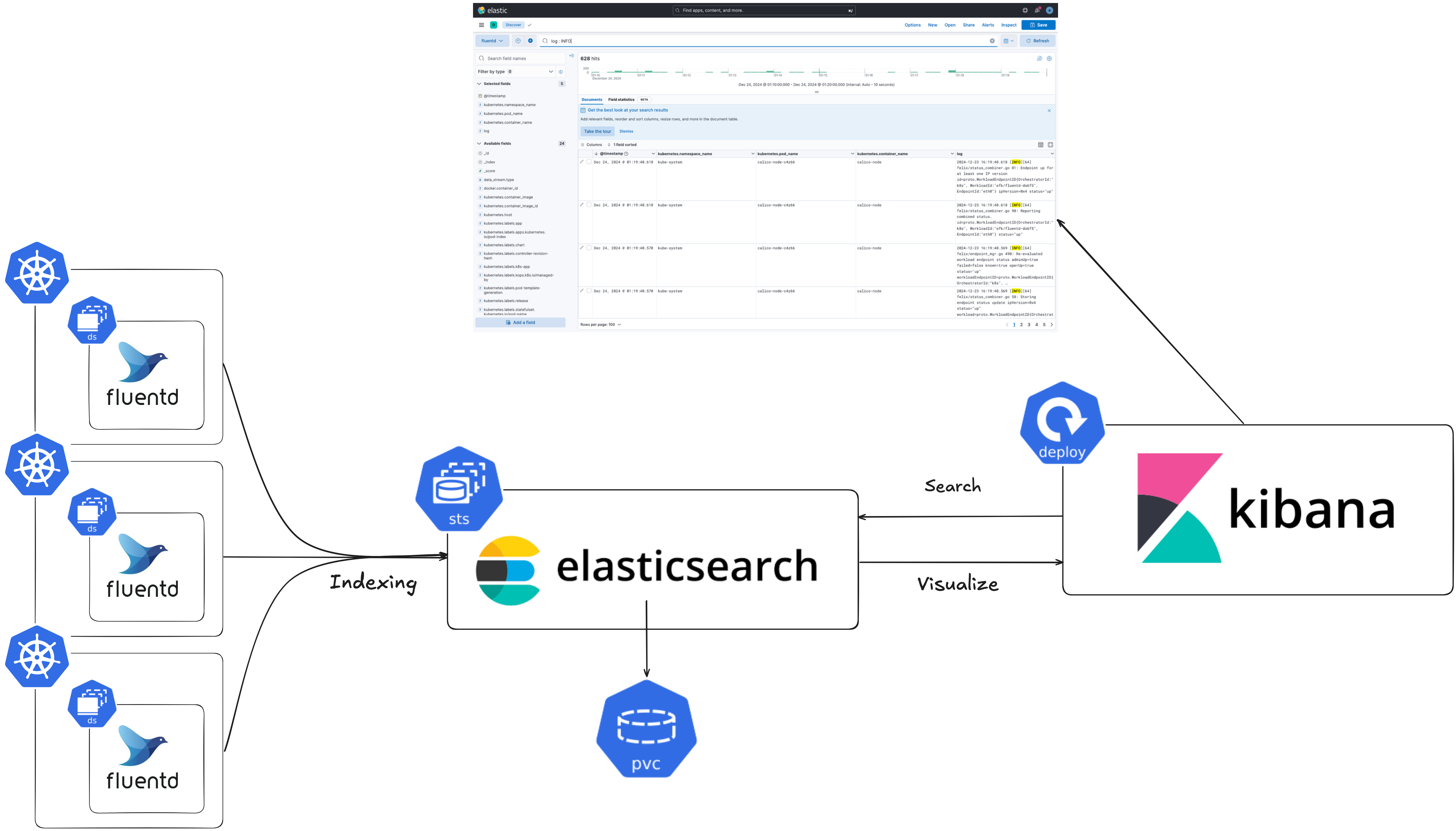
위 그림과 같이 Fluentd를 DaemonSet으로 배포하여 각 노드의 컨테이너 로그를 수집하였고, 이를 Elasticsearch에 전달하여 저장 및 인덱싱하는 구조로 구축하였습니다. 실제 구현은 Elastic과 Fluentd의 Helm Repo에서 제공하는 Helm 차트를 활용하여 배포했으며, 수집된 로그 데이터는 Kibana의 웹 인터페이스를 통해 fluentd-* 인덱스 패턴을 생성하여 시각화하였습니다.
EFK 스택을 선택한 이유는 크게 두 가지입니다. 먼저 EFK 스택과 PLG(Promtail, Loki, Grafana) 스택을 비교했습니다. PLG 스택은 라벨 기반의 단순한 로그 검색 구조로 모놀리식 아키텍처에 최적화되어 있습니다. 반면 EFK 스택은 Elasticsearch의 전체 텍스트 검색 기능과 복잡한 쿼리를 지원하여 여러 서비스의 로그를 효과적으로 검색하고 분석할 수 있어 MSA(Micro Service Architecture)에 최적화되어 있습니다. 저희 프로젝트는 여러 개의 서비스를 운영하는 MSA(Micro Service Architecture)를 채택했기 때문에, Loki보다는 Elasticsearch를 활용하는 것이 적절하다고 생각했습니다. 또한 ELK(Elasticsearch, Logstash, Kibana) 스택대신 EFK를 선택하였습니다. 저희 프로젝트는 여러 개의 서비스 로그를 수집하고 검색하는 기본적인 기능만 필요했기 때문에, Logstash보다는 리소스 사용량이 적고 가벼운 Fluentd가 더 적합하다고 판단했습니다.
실제 운영 환경에서 EFK 스택을 효과적으로 활용하기 위해서는 아직 많이 부족합니다. 로그 검색을 효율적으로 하기 위해 Elasticsearch의 Query DSL도 공부해야 하며, 로그 데이터가 증가할 경우를 대비해 Elasticsearch의 HPA(Horizontal Pod Autoscaler) 구성 방법도 알아야 합니다. 이 부분은 제가 앞으로 더 공부해야 한다고 생각합니다.
2.4 Recipe Review Service
이번 프로젝트에서 저는 주로 쿠버네티스 기반 클라우드 네이티브 애플리케이션 설계와 인프라 구성을 담당했습니다. 운영자 역할을 맡았지만, 백엔드 서비스의 코드 구조를 이해하는 것이 백엔드 개발자와의 협업과 전체 시스템 설계에 도움이 될 것으로 생각했고, 팀의 백엔드 개발자분의 뛰어난 개발 노하우도 배우고 싶어서 Recipe Review Service를 개발하게 되었습니다. 개발 과정은 팀 백엔드 개발자분의 Ingredients Manage Service 코드를 보고 이해한 후, 이를 Recipe Review Service에 적용하는 방식으로 진행되었습니다. 이를 통해 협업을 위한 저의 노력과 실무에서도 선임 개발자의 코드를 이해하고 적용할 수 있다는 점을 보여드리고 싶습니다.
다만 제가 백엔드 서비스 개발을 맡게 되면서, 서비스 간 통신을 추적하는 분산 추적(Distributed Tracing) 시스템, 트래픽에 따른 오토스케일링과 같은 인프라 요소를 구현하지는 못했습니다. 또한 Recipe Review Service에서 TestContainer 기반 테스트 코드 작성과 Redis를 활용한 캐싱 기능도 아쉽지만 구현하지 못했습니다. 하지만 신입 개발자로서 시스템의 전반적인 부분을 경험해 보는 것이 더 중요하다고 판단했고, 실력 있는 개발자에게 배울 기회를 놓치고 싶지 않아 이런 선택을 하게 되었습니다.
Recipe Review Service는 MongoDB를 데이터베이스로 사용하여 레시피 리뷰의 생성, 조회, 수정, 삭제(CRUD) 기능을 제공하는 서비스입니다. 자세한 개발 내용은 Recipe Review Service 리포지터리에서 확인하실 수 있습니다.
💭 3. Project Retrospective
Liked (좋았던 점)
이번 프로젝트에서 가장 좋았던 점은 쿠버네티스 기반 클라우드 네이티브 애플리케이션을 직접 설계하고 구축하여 배포까지 경험해 볼 수 있었다는 것입니다. 사실 이런 프로젝트는 기술적인 지식뿐만 아니라 클라우드 인프라 비용도 많이 필요한데, 카카오테크 부트캠프에서 AWS 비용을 지원해 주셔서 실제 클라우드 환경에서 쿠버네티스 클러스터를 구축하고 운영해 볼 수 있었습니다.
무엇보다도 팀원 구성이 정말 좋았습니다. 뛰어난 백엔드 개발자분이 계셔서 제가 설계한 내용을 빠르게 구현해 주셨고, 덕분에 인프라를 구축하는 데 더 집중할 수 있었습니다. 또한 중간에 프론트엔드 개발자분이 빠지게 되었지만, 오히려 이를 계기로 백엔드 시스템 전반에 더 집중할 수 있었습니다.
MSA(Micro Service Architecture)를 직접 설계하고 쿠버네티스에 배포하기까지의 모든 과정을 경험할 수 있었고, 제가 작성한 코드와 설계한 시스템이 실제로 구현된 코드가 남아있어서 나중에 실무에서도 많은 도움이 될 것 같습니다.
Learned (배운 점)
이번 프로젝트를 통해 클라우드 네이티브 애플리케이션 개발에 필요한 다양한 기술을 배울 수 있었습니다. 특히 Event-Driven Architecture, 중앙 집중식 설정 관리, 데이터베이스 Master-Slave Replication 등 다양한 기술을 저희 프로젝트에 적용해 보면서 각 기술의 장단점과 실제 적용 시 고려해야 할 점을 자세히 배울 수 있었습니다.
쿠버네티스는 처음 사용해 보는 기술이었지만, 쿠버네티스의 다양한 오브젝트를 직접 구성하고 배포해보면서 쿠버네티스와 관련된 기술도 정말 많이 배울 수 있었습니다. 특히 쿠버네티스 기반 클라우드 네이티브 환경에서 애플리케이션을 실행하기 위해 필요한 요소와 각 요소의 역할을 확실히 이해할 수 있었습니다.
DevOps 관점에서도 정말 많은 것을 배웠습니다. 실제 서비스에서 개발자와 운영자가 효율적으로 협업하기 위해 어떤 것이 필요하고 왜 필요한지 이해할 수 있었습니다. 그뿐만 아니라 DevOps 환경을 직접 구축해보면서 CI/CD Pipeline, Metrics Monitoring, Logging System과 같은 기술에 대해서도 배울 수 있었습니다.
백엔드 개발 측면에서는 잘하는 백엔드 개발자분의 코드를 보면서 프로젝트 구조를 어떻게 잡고 예외는 어떻게 처리하는지와 같은 노하우를 배울 수 있었고, 제가 담당했던 Recipe Review Service를 개발할 때 직접 적용해볼 수 있었습니다.
Lacked (부족했던 점)
쿠버네티스와 클라우드 네이티브 애플리케이션은 프로젝트 시작 전에 두 달 정도 공부했습니다. 두 기술 모두 처음 접하고 실제로 적용해 보는 거라 3개월이란 시간이 너무 짧게 느껴졌습니다.
아직 실제 서비스로 운영되기에는 매우 부족한 프로젝트입니다. Rate Limiter와 서킷 브레이커 패턴을 적용하여 시스템의 안정성을 높여야 하며, 오픈텔레메트리(OpenTelemetry)와 템포(Tempo)를 활용한 분산 추적(Distributed Tracing) 시스템도 구축해야 합니다. 또한 트래픽에 따른 오토스케일링도 적용해야 하며, 데이터베이스의 경우 MongoDB는 ReplicaSet을 통해 자동 failover가 가능하지만, MariaDB는 Master DB 장애 시 Slave DB를 Master로 승격시키는 자동 failover 기능을 추가로 구현해야 합니다.
백엔드 측면에서 Recipe Review Service는 TestContainer를 사용한 테스트 코드 작성과 Redis를 활용한 캐싱 기능이 아직 구현되지 않았습니다. 또한 Spring Cloud Config 대신 Kubernetes의 Kustomize를 활용한 환경별 설정 관리 방식으로 전환하는 중이었는데, 두 방식의 장단점을 제대로 비교해 보지 못한 채 프로젝트가 끝났습니다.
무엇보다도 프론트엔드 개발자가 중간에 나가게 되어 프론트엔드 개발을 완성하지 못한 게 가장 아쉽습니다. 하지만 부족한 점을 아는 것부터가 성장의 시작이라 생각하며, 앞으로의 프로젝트에서는 이러한 부분을 하나씩 보완해 나갈 계획입니다.
Longed for (바라는 점)
앞서 언급했던 부족한 부분을 하나씩 보완해 나가면서, ZipBob 프로젝트를 실제 서비스 수준의 완성도로 만들고 싶습니다. 특히 프론트엔드와의 연동이 완료되면 E2E 테스트로 전체 시스템을 검증하고, JMeter를 활용한 성능 테스트로 병목 지점을 찾아 개선해보고 싶습니다.
이번 프로젝트를 통하여 배운 기술과 경험이 저의 커리어의 소중한 밑거름이 되길 바라며, 앞으로도 끊임없이 성장하는 엔지니어가 되도록 하겠습니다.
📚 4. Reference
Github Repository
Repositories Written by Me
| Github Repository | Description |
|---|---|
Recipe Review Service |
AI Service가 추천한 레시피에 대한 리뷰를 관리하는 서비스 |
Zipbob Deployment |
전체 애플리케이션의 인프라와 개발/배포 환경, DevOps 관련 저장소 |
Repositories Written by Team Members
| Github Repository | Description |
|---|---|
Ingredients Manage Service |
사용자의 냉장고 재료를 관리하는 서비스 |
Config Service |
각 서비스의 설정을 중앙 집중적으로 관리하는 서비스 |
Edge Service |
API Gateway와 사용자 인증/인가를 처리하는 서비스 |
Recipe Crawler |
레시피 데이터 수집을 위한 크롤링 관련 저장소 |
AI Service |
RAG 기반 레시피 추천 서비스 |
Reference Books
| Title | Author | Publisher |
|---|---|---|
클라우드 네이티브 스프링 인 액션 |
토마스 비탈레 지음, 차건회 옮김 | 제이펍 |
시작하세요! 도커/쿠버네티스 |
용찬호 지음 | 위키북스 |
쿠버네티스 완벽 가이드 |
마사야 아오야마 지음, 박상욱 옮김 | 길벗 |
Project-Related Studies
| Github Repository | Description |
|---|---|
| polar-deployment | 클라우드 네이티브 스프링 인 액션 책의 Polar 애플리케이션 배포 실습 관련 저장소 |
| polar-config-service | 클라우드 네이티브 스프링 인 액션 책의 Config Service 실습 |
| polar-config-repo | 클라우드 네이티브 스프링 인 액션 책의 Config Service의 설정 저장소 |
| polar-edge-service | 클라우드 네이티브 스프링 인 액션 책의 Edge Service 실습 |
| polar-dispatcher-service | 클라우드 네이티브 스프링 인 액션 책의 Dispatcher Service 실습 |
| polar-catalog-service | 클라우드 네이티브 스프링 인 액션 책의 Catalog Service 실습 |
| polar-order-service | 클라우드 네이티브 스프링 인 액션 책의 Order Service 실습 |
| kubernetes | 쿠버네티스 공부 정리 |